Let's Discuss
Enquire NowConcord Capture
Machine Learning
NLP
Automated Document Capture
Rest assured, we have a strict no-spam policy.
Your inbox is safe with us!
Your inbox is safe with us!

BUSINESS REQUIREMENT
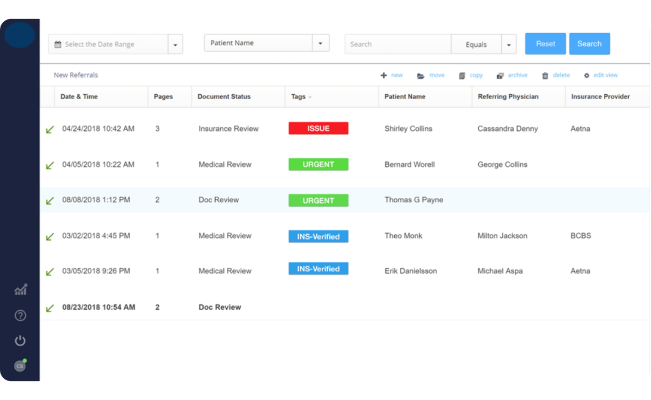
- Ability to process multiple formats of document/ images coming from various sources.
- Extract certain data and patterns present in unstructured document/images.
- Feature to add/ review new rules or data patterns for extracting definitive fields from faxed images.
- Setup RPA pipeline to process incoming documents, extract all the relevant information across various stages.
SOLUTIONS
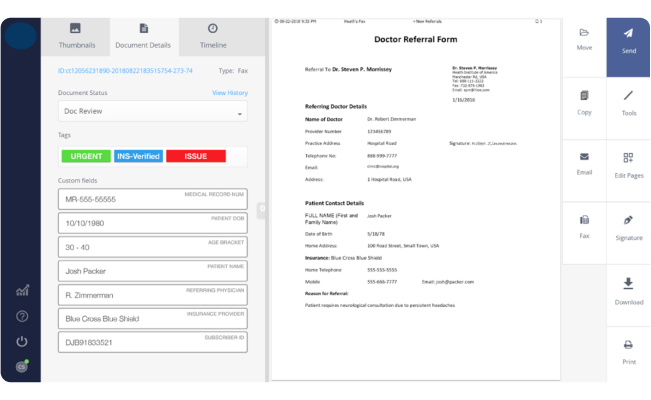
- Preprocessing and image segmentation is done using Leptonica. Tensorflow and Leptonica are used to clean up unwanted sections/identify sections having possible textual contents
- The identified possible high-value sections are fed to an OCR module, which extracts the raw text.
- The text is fed to a dynamic rule-based NLP Engine to extract the required data. It gives us the ability to add rules on the fly without recomputing the rules model.
- All these components are hooked up to an RPA pipeline. Each module in the pipeline exposes custom control APIs which are used by the RPA pipeline to monitor and control the flow of documents into each stage of the pipeline.
- All individual modules were dockerized and deployed to the production environment using Kubernetes. The RPA pipeline plays a role in the deployment orchestration and determines the number of instances of each pipeline stage to handle and distribute the workload.
KEY TECHNOLOGIES
- Open CV
- Leptonica
- TensorFlow

More Projects
Category :