Let's Discuss
Enquire NowDocument Extraction using LLM’s
Machine Learning
Extracting Structured Information from Scanned Documents using LLM’s
Your inbox is safe with us!

Description
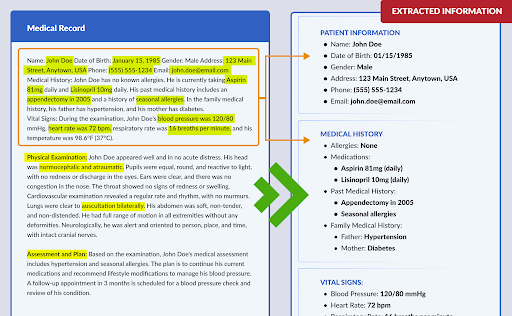
The problem of extracting information from scanned documents, including PDFs and other complex formats like TIFFs, has been the subject of work for over a decade. With the recent advent of Large Language Models (LLMs), the solution to this problem has undergone a complete change, becoming more accurate and budget-friendly. However, this is not simply about throwing a document at an LLM and asking it to perform the task of structured information extraction. Our aim is to save time by eliminating the manual extraction of information and effectively automating the entire process with our AI-powered automated document capture software.
A customizable solution for automating the extraction of relevant information from scanned documents of any format has been developed by integrating an On-premise Language Model (LLM), which operates locally or within a specific physical infrastructure, and a custom-made semantic matcher – Mandrake, which is a custom designed oncology and morphology-based semantic matcher. It automates the identification of groups or patterns of characters, which can be used to extract relevant data from a larger text. The software is also integrated with an e-fax system like Concord that enables users to access PCI and HIPAA secure fax online and Tesseract, which is an open-source OCR engine.
Business Requirement
- The objective was to create software that can efficiently extract relevant information from various scanned documents accurately and enhance the efficiency of record processing.
- The software should have a high level of accuracy in extracting relevant information from various document formats. It should be able to precisely identify and extract the required data fields, minimizing errors and false positives.
- Should support integration with other software applications, databases, or document management systems, enabling automated data transfer and streamlined processing of the extracted information. Should also prioritize data privacy and security, adhering to industry standards and regulations to safeguard sensitive information
- Should provide insightful analytics and reporting functionalities to assist in deriving meaningful insights from extracted data for decision-making and research purposes.
SOLUTIONS
- An automated document capture software solution was developed incorporating an integrated On-premise LLM, ensuring data privacy and control while enhancing accuracy and efficiency in extracting relevant information. It can seamlessly process documents, records and extract key data points.
- OCR technology was incorporated for text detection and identification of relevant information, along with the natural language understanding capabilities of the LLM and the custom-made semantic matching algorithms of Mandrake, ensuring accurate identification and extraction of relevant content.
- The architecture is flexible, capable of processing diverse document types and incorporating updates to accommodate new formats. The LLM and Mandrake models are continuously refined to enhance accuracy and keep up with the latest medical terminology and regulations.
- Robust data protection measures, such as encryption, access controls, and compliance with privacy regulations, are implemented to safeguard information at all stages of extraction and processing.
FEATURES
- On-Premise LLM Integration – The software architecture incorporates the integration of a On-premise LLM, to leverage its natural language understanding capabilities for accurate comprehension of terminology and context, ensuring data privacy, security, and control within the organization’s infrastructure, while also providing faster processing and reduced latency compared to cloud-based services.
- Custom-Made Semantic Matcher (Mandrake) – A custom-made semantic matcher, known as Mandrake, is utilized for precise identification, pattern-matching and extraction of relevant content in documents.
- Data Validation and Verification – Intelligent algorithms are employed for data validation and verification, ensuring accuracy and consistency across medical records.
- Document Format Flexibility – Document format flexibility is enabled, allowing the software to handle various formats such as scanned documents, PDFs, and electronic health records (EHR) for comprehensive extraction.
KEY TECHNOLOGIES
- Python
- Java
- ReactJS
- MongoDB
- Tesseract