Let's Discuss
Enquire NowLambda Vs Kappa
Dec 1, 2021by, Afshan K Rahman
Data Science
Machine Learning
There has always been a puzzlement amongst the developers when it comes to deciding between Lambda or Kappa architectures. Wondering what Lambda and Kappa are??
Well, these are some major big data processing architectures. Data processing architectures are designed to manage the ingestion, processing, and analysis of large volumes of data,(say the BIG data!!!)
Now let us dig deep into Lambda and Kappa architectures.
What is Lambda Architecture?
It is a real-time data processing architecture that processes the streaming data by utilizing batch and stream processing techniques. Alright, I got it, you might be oblivious about the batch and stream processing mentioned here. Let us have a close look over the architecture then!
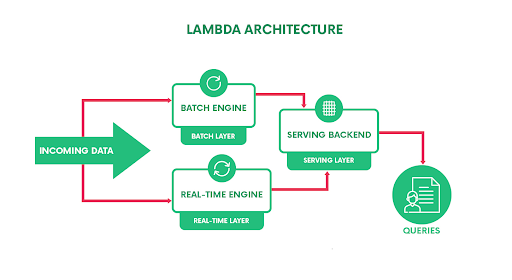 As in the figure, Lambda architecture is composed of three layers basically.
As in the figure, Lambda architecture is composed of three layers basically.
Batch Layer
It has got 2 major functions:
- To manage the immutable, append-only raw streaming data.
- To precompute the batch views.
Real-Time Layer
You may come across the terms Speed layer or Streaming layer around the web analogous to this layer of Lambda Architecture, but for better understanding lets call it Real-time layer. You might have figured out what this layer does by now. Yes, it computes the real-time views instead of batch views!
Serving Layer
It queries the batch and real-time views and merges them both.
Let’s try to have an understanding of what really happens to the incoming data in these layers.
The incoming data is dispatched to both Batch and Real-time layers. A batch is a bounded set of data, with a start and an end. In the batch, layer computation takes place in an iterative manner over the historical data, while the real-time layer provides us with access to the latest data.The serving layer collects and merges the results from both layers and provides a complete answer for the query.
What is Kappa Architecture?
Kappa simplifies the Lambda architecture by handling both real-time data processing and continuous data processing using a single stream processing engine. That means, the incoming data is streamed through the real-time layer and the results are placed in the serving layer.
Going by the architecture, as shown below,
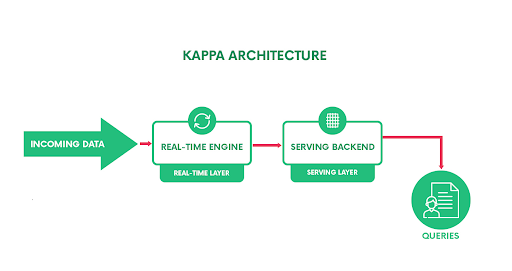 As it is evident from the figure, there is just the real-time layer in this architecture that handles all data processing. This layer sequentially processes all the input data points and generates real-time views until the application is stopped or the input pipeline is exhausted.
As it is evident from the figure, there is just the real-time layer in this architecture that handles all data processing. This layer sequentially processes all the input data points and generates real-time views until the application is stopped or the input pipeline is exhausted.
Why Lambda?
There are many use cases where the developers opt to go with Lambda architectures while dealing with data. Let’s go with an example.
Consider you are to find out why your app crashed(Oh, that is saddening…. but just assume), given the crash logs, which data processing architecture would you choose? Well, Lambda must be your choice, will tell you why.
In the above example, there are several historical logs that are available to you along with the streaming new data. The historical logs are computed as batches by the batch layer, and the new incoming data are processed in the real-time layer. Hope that’s clear!
Lambda is preferred over Kappa for cases that involve a different set of logical calculations, as these have two parallel layers to ease the process. Or simply, in cases where the batch layer and real-time layer have different application logic, Lambda should opt.
Well to jot down the pros (You probably would see these listed in many related blogs, so I won’t go into much detail).
Pros :
- It retains the input data unchanged
- Processing of data is accurate and precise as any loss in accuracy of views computed by the real-time layer can be recovered by the batch layer when it visits the input data points at a later point in time.
- Fault-tolerant to human errors in the real-time layer.
- Scalable architecture for data processing
Why not Lambda?
If you are making any code-level changes, for Lambda these changes are to be made to both batch and real-time layers. And any cumulative stacks which are generated by the batch layer must be cleared before reprocessing the old data through the batch layer again so that new application logic reflects in the serving layer data.
Cons:
- Two separate code bases for the batch and real-time layers.
- Reprocess every batch cycle which is not beneficial for all scenarios.
How about Kappa?
As Lambda requires maintaining different codebases for each of its layers, Kappa came into the scene. Kappa is never a substitute for Lambda, instead, we can put it up as an alternative. Since it has only one layer, implementing application logic changes is comparatively easier. And in order to reflect these changes to serving layer data, all that you have to do is reset the input stream to the real-time layer. This will automatically rewrite the stale results based on old logic in the serving layer with that of the updated logic.
Pros :
- Reprocessing only when the code is changed.
- Makes optimization easier, since only a single layer is present.
- Lower memory and CPU resource requirements when compared to Lambda.
Cons :
- Unable to perform logical/cumulative computations which require a large subset of historical data as input.
- Since there is no batch layer, It lacks the ability to improve the accuracy of generated real-time views, later on. (This is possible in Lambda since the batch layer can revisit all the input data points previously processed by the speed layer at least once.)
If the batch and streaming analysis are identical, then using Kappa is probably the best solution. Now for example, if we consider the previous case of processing the logs, where no comparison is required, Kappa can be the best choice.
Lambda Or Kappa?
Due to the difference in architecture layout, it would be unprofessional to declare one of these approaches as the best for all scenarios. The better approach would be to do a proper analysis of the use-case you are facing and see which approach suits you best. Generally, we can say that Kappa gives you the ability to stream lots of data in near real-time, by limiting the subset of data it can view/process at a time. While Lambda enables us to perform complex operations over a large time frame of input by sacrificing near real-time throughput for such operations and maintaining near real-time throughput for other operations. Now that you have an idea of what these architectures are, the capabilities they could offer, you can decide which architecture to go with.
Have a project in mind that includes complex tech stacks? We can be just what you’re looking for! Connect with us here.
Disclaimer: The opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Dexlock.



