Let's Discuss
Enquire NowPerformant cross-platform deep learning with tvm.ai
Nov 29, 2021by, Harikrishnan
Artificial Intelligence
Machine Learning
Introduction
Tvm.ai is an open compiler and accelerator stack that allows one to run deep learning models on basically any environment. It seeks to fit into the gap between highly optimized backend-specific solutions and usability-focused general frameworks like TensorFlow. It began at SAMPL as a research project and is now being developed on GitHub by a lot of contributors.
Let’s see how tvm.ai enables this sort of cross-platform compatibility.
A Few Interesting Examples
For example,
One can write a function in C++ to add two vectors:-
The above function is a type-erased function that can accept inputs of any type such as:-
- int, float, and string
- Another PackedFunc
- Module for compiled modules
- DLTensor* for tensor object exchange
- TVM Node to represent any object in IR
It can either be called from C++ itself:-
Or dynamically from a language like a python or javascript after registering it (thanks to its type-erased property):-
TVM_REGISTER_GLOBAL("addTwoVectors")
.set_body(addTwoVectors);
And then call it from python like this:-
import tvm
addTwoVectors = tvm.get_global_func("myadd")
print(addTwoVectors(1, 2))
Running code on Embedded Targets
TVM also allows one to run compiled code on embedded targets such as smartphones, RaspberryPI, ARM chips, etc.
Testing on these devices is made easier by using the in-built RPC server:-
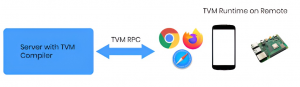
Instead of compiling, and then deploying the final code; for easier development one can:-
- Start an RPC server on the embedded host
- Cross-compile the kernel on a local machine with the target’s configuration
- Remotely upload and run the kernel on the client.
This RPC server is a part of the runtime of the target. This RPC-based testing provides the benefit of quick feedback and allows the user to verify the correctness of the results by copying them back to the local machine and also allows profiling of the kernel code.
The Mechanism
Modules and PackedFuncs are the fundamental way that tvm.ai supports cross-platform computation.
PackedFuncs
These are type-erased functions, as mentioned before, that can be called from languages like python, javascript, C++, etc. The PackedFuncs abstraction solves many problems that come up in system-level design and debugging of cross-platform compilers:-
- Debugging is made easier as a user can define a function in python and call it from a compiled function.
- Linking allows one to call, say CUDA code from a compiled host using a function
- Prototype and define an Intermediate Representation pass in python and invoke from C++
Modules
These are compiled objects that are run on various hosts such as CUDA, ROCM, ARM, x86, etc. The module contains PackedFunc and on the first call, the function handle is cached and reused on subsequent calls.
Another abstraction – ModuleNode(an Abstract Class) is used by each device to implement the required logic. This abstraction allows new devices to easily be integrated into the existing system, and therefore we don’t need to generate host code for every new device.
Nodes
All language objects in the compiler stack are subclassed from the Node base class. This allows the developer to be able to serialize any language object or Intermediate representation.
In addition, the developer is able to explore, print, and manipulate IR objects in the front-end language for rapid prototyping.
Internal Representation in tvm.ai
The optimization in tvm.ai is achieved by using an intermediate representation(IR). Popular frameworks like Tensorflow, NNVM, etc use a computation graph representation that is helpful in optimizing for memory reuse, automatic differentiation, etc. TVM specifically uses a lower-level IR to express its deep-learning computations. If you are familiar with Halide, a programming language for high-performance Image Processing, you will know that it helps speed up the algorithms by parallelizing and speeding up the common loop operations that are performed in image processing; TVM extends this language with custom IR nodes specific to deep-learning and then speeding up the operations represented in this extended IR.
Have a project in mind that includes complex tech stacks? We can be just what you’re looking for! Connect with us here.
Disclaimer: The opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Dexlock.



