Let's Discuss
Enquire NowAir Quality Prediction System using LightGBM
Jul 21, 2022by, Mythili.S
Machine Learning
Air pollution is a major concern to the environment and air quality index. The air quality index (AQI) is an index used for reporting the daily air quality. It is a measure of how air pollution affects one’s health within a short period of time. By getting updates of AQI, one can understand how the local air quality affects health. Higher the value of AQI, greater the risk factor with high levels of air pollution and greater the health concerns. India follows a 500 point scale to report air quality where a rating in the range 0-50 is considered good and a rating in the range 300-500 is deemed hazardous. Generally, AQI values at or below 100 are considered satisfactory and a value above 100 as unhealthy.
An air quality prediction system based on a machine learning framework LightGBM model is used for the air quality prediction. The air quality over a particular area can be predicted 24 hours in advance by using hourly data of both historical air quality data and meteorological data within a time span of three years.
Dataset Requirements
A total of three datasets are required for the prediction of air quality: air quality dataset, meteorological dataset and meteorological forecast dataset. The first two datasets are the hourly data of pollutants and meteorological factors respectively. The pollutant parameters considered are PM10, PM2.5, NO2, NOx, NO, O3, SO2, CO. The meteorological factors include Wind direction (WD), Wind speed (WS) and Relative humidity (RH), Atmospheric temperature (AT) and Barometric pressure (BP). The third dataset is the hourly meteorological forecast data of any random day other than those used in training the model. The parameters considered in this dataset are the same as those in the meteorological dataset. The first two datasets are used for training the model and the third dataset is used in testing the model.
Why LightGBM?
Light Gradient Boosting Method or LightGBM is a gradient boosting framework which makes use of tree based learning algorithms. LightGBM grows trees vertically while the other algorithms grow trees horizontally. The leaf with max delta loss is chosen to grow. When growing the same leaf, the Leaf-wise algorithm can reduce more loss than a level-wise algorithm. LightGBM can handle the large data size and takes less memory to run.
Modules in the Air Quality Prediction System
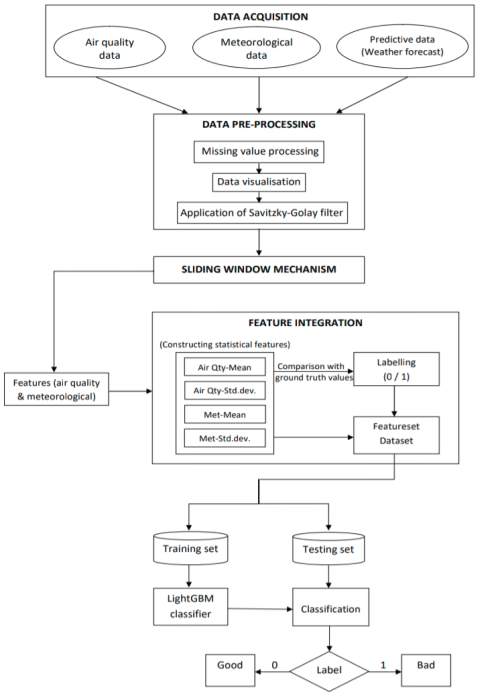
Data pre-processing: The datasets are checked for any missing values and replaced. This resultant dataset is then visualised using matplotlib library to understand the trend of the data over time. Savitzky-Golay filter is applied for the purpose of smoothing the provided data. The resultant datasets are the pre-processed datasets.
Sliding window mechanism: The use of preceding time steps to predict the subsequent time step is known as the sliding window method. The time-stamped dataset is often restructured as a supervised learning problem by using the value at the previous time step for prediction of value at the subsequent time step. The use of previous time steps to predict the subsequent time step is known as the sliding window method. In statistics and time series analysis, this is known as the lag method.
Feature integration: Feature integration is to deeply mine the features which may significantly influence the predictors to produce the prediction model. Four characteristics to be dealt with here are the air quality feature, the meteorological feature, the predictive data feature, and the statistical feature.
Data Splitting: The new dataset is split into two, training set and testing set. The testing set is never used for training as it can lead to the overfitting of the model.
Model training and testing: The LightGBM model is trained by fitting the training set to the LightGBM classifier model. The classifier model upon testing, categorises the air quality into good or bad. The resultant classifications are fairly close to the testing set.
#training
model = ltb.LGBMClassifier()
#model = ltb.LGBMClassifier(max_depth=4,num_leaves=25,learning_rate=.05)
#param={'objective':'binary'}
model.fit(X_train, y_train,eval_set=[(X_test, y_test), (X_train, y_train)])
|
#testing
A=len(X_test)
res1 = []
for i in range(0,A):
predicted_y = model.predict(X_test)
if(predicted_y[i]==0):
res1.append('Good')
else:
res1.append('Bad')
|
Prediction: For predicting the air quality of a particular day, the meteorological forecast data of that day is provided. Air quality data of any nearby day is additionally provided. This data is to be pre-processed, sliding window is to be applied, statistical features of the two datasets are extracted and is used for the air quality prediction of that desired day.
Conclusion
LightGBM is a suitable framework for air quality with high accuracy, such that it is a much better framework candidate for air quality prediction than the other prevalent models. More meteorological factors like precipitation, maximum and minimum temperature, vapor pressure, solar radiation, etc. can be considered to increase the accuracy of the system.
Looking to implement the latest innovative technologies? We at Dexlock holds significant expertise in ML that can be just what you are looking for. Through our skills we deliver only the finest to fellow futurist thinkers who wants to make an impact in tech world. Connect with us here to give wings to your dreams.
Disclaimer: The opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Dexlock.



