Let's Discuss
Enquire NowAre Vision Transformers Worth The Hype?
Oct 19, 2022by, Pooja Ramesh
NLP
The Vision Transformer (ViT) first appeared in 2022 as a competitive alternative to convolutional neural networks (CNNs), which are currently the state-of-the-art in computer vision and are widely utilized in image identification applications. In terms of computational efficiency and accuracy, ViT models exceed the present state-of-the-art (CNN) by almost a factor of four.
In natural language processing, transformer models have become the de-facto standard (NLP). Vision Transformers (ViTs) and Multilayer Perceptrons have lately sparked interest in computer vision research (MLPs).
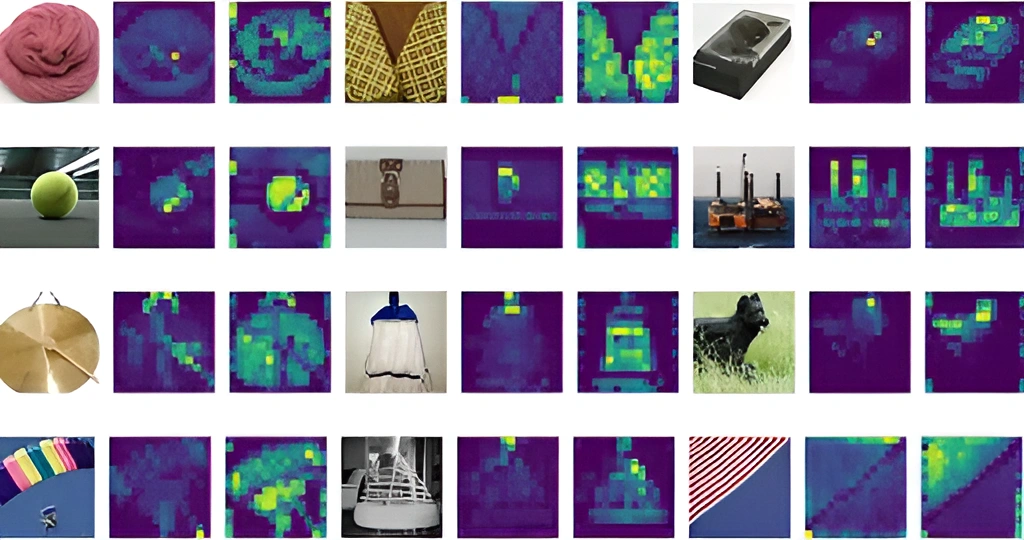
Image Credit: ViT
Vision Transformer (ViT) in Image Recognition
While the Transformer design has become the industry standard for natural language processing (NLP), it has only a few implementations in computer vision (CV). Attention is employed in computer vision either in conjunction with convolutional networks (CNN) or to substitute some parts of convolutional networks while maintaining their overall composition. This reliance on CNN is not required, as a pure transformer applied directly to image patch segments can perform remarkably well on image classification tasks.
Vision Transformers (ViT) recently obtained outstanding results in benchmarks for a variety of computer vision applications, including image classification, object recognition, and semantic picture segmentation.
What is a Vision Transformer (ViT)?
“An Image is Worth 16*16 Words: Transformers for Image Recognition at Scale,” a research article presented as a conference paper at ICLR 2021, unveiled the Vision Transformer (ViT) paradigm. Neil Houlsby, Alexey Dosovitskiy, and ten other Google Research Brain Team authors created and published it.
The fine-tuning code and pre-trained ViT models can be found on Google Research’s GitHub.
The ImageNet and ImageNet-21k databases were used to train the ViT models.
Are Transformers a Deep Learning method?
In machine learning, a transformer is a deep learning model that uses attention processes to weight the significance of each element of the input data differently. Machine learning transformers are made up of many self-attention layers. Natural language processing (NLP) and computer vision are two AI subfields that employ them extensively (CV).
Machine learning transformers hold great potential for a generic learning method that can be used to a variety of data modalities, including recent advancements in computer vision that have achieved state-of-the-art standard accuracy while reducing parameter usage.
Difference between CNN and ViT (ViT vs. CNN)
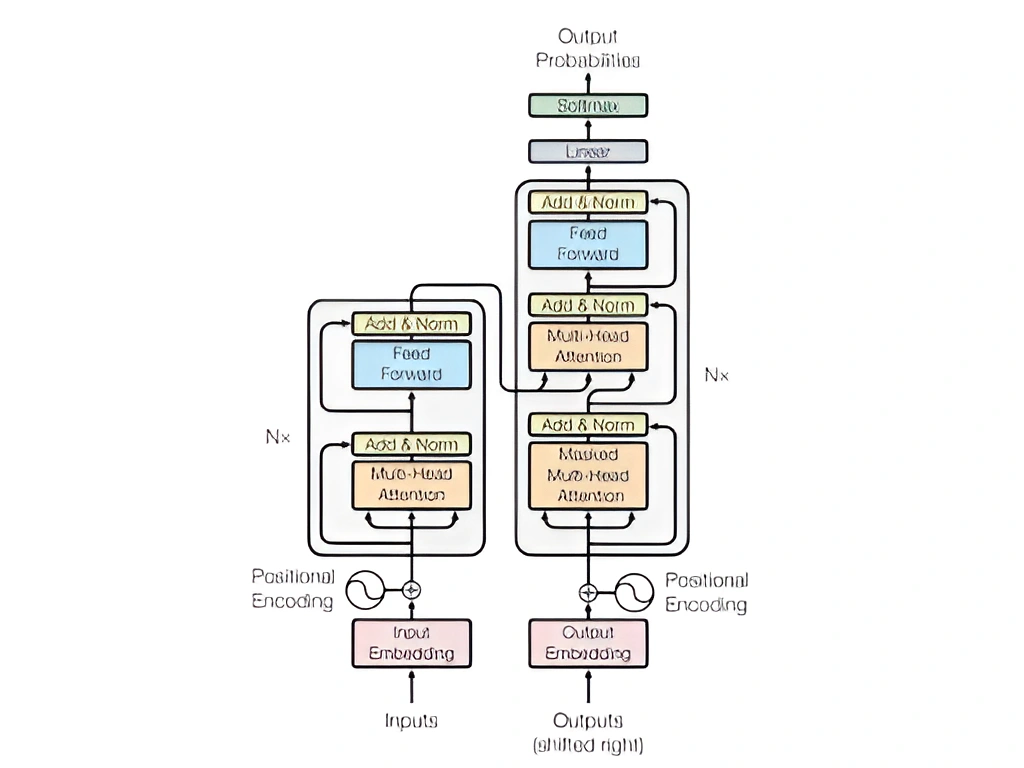
Image Credit: Literature Review
When compared to convolutional neural networks (CNN), Vision Transformer (ViT) offers impressive outcomes while using less computer resources for pre-training. When training on fewer datasets, Vision Transformer (ViT) has a weaker inductive bias than convolutional neural networks (CNN), resulting in a greater reliance on model regularization or data augmentation (AugReg).
The ViT is a visual model based on a transformer’s architecture, which was initially created for text-based operations. The ViT model represents an input image as a series of image patches, similar to how word embeddings are represented in text when employing transformers, and predicts class labels for the image directly. When trained on enough data, ViT outperforms an equivalent state-of-the-art CNN using 4x fewer CPU resources.
When it comes to NLP models, these transformers have a high success rate, and they’re currently being used on photos for image recognition tasks. ViT separates the images into visual tokens, whereas CNN employs pixel arrays. The visual transformer separates a picture into fixed-size patches, embeds each one appropriately, and passes positional embedding to the transformer encoder as an input. Furthermore, ViT models beat CNNs in terms of computing efficiency and accuracy by nearly four times.
ViT’s self-attention layer allows you to embed information globally throughout the entire image. The model also uses training data to represent the relative locations of image patches in order to recreate the image’s structure.
The transformer encoder consists of the following components:
- MSP (Multi-Head Self Attention Layer): This layer concatenates all of the attention outputs to the right dimensions in a linear fashion. The several attention heads in an image aid in the training of local and global dependencies.
- MLP (Multi-Layer Perceptrons) Layer: This layer is made up of two layers, each with a Gaussian Error Linear Unit (GELU).
- LN (Layer Norm): Because it does not include any additional dependencies between the training pictures, it is added before each block. As a result, the training time and overall performance are improved.
Additionally, residual connections are provided after each block because they allow components to flow directly through the network without having to go through non-linear activations.
In the case of image classification, the MLP layer implements the classification head. It uses one hidden layer and a single linear layer for fine-tuning during pre-training.
How does a Vision Transformer (ViT) work?
A vision transformer model’s performance is influenced by the optimizer’s choice, network depth, and dataset-specific hyperparameters. ViT is more difficult to optimize than CNNs.
The difference between a pure transformer and a CNN front end is to marry a transformer to a CNN front end. A 16*16 convolution with a 16 stride is used in the standard ViT stem. A 3*3 convolution with stride 2 on the other hand, improves stability and precision.
CNN creates a feature map out of simple pixels. A tokenizer then converts the feature map into a sequence of tokens, which are subsequently fed into the transformer. After then, the transformer uses the attention strategy to generate a series of output tokens. A projector eventually connects the output tokens to the feature map.. The latter enables the investigation to navigate potentially important pixel-level details. As a result, the number of tokens that must be evaluated is reduced, cutting expenditures dramatically.
The ViT model can outperform the CNNs when trained on large datasets with over 14 million images. If not, sticking with ResNet or EfficientNet is the best option. Even before fine-tuning, the vision transformer model is trained on a large dataset. The only difference is that the MLP layer has been removed and a new D times KD*K layer has been added, where K is the number of classes in the tiny dataset.
The 2D representation of the pre-trained position embeddings is used to fine-tune in higher resolutions. This is because the positional embeddings are modeled by the trainable liner layers.
Conclusion
In Computer Vision, the vision transformer model employs multi-head self-attention without the need for image-specific biases. The model divides the images into a series of positional embedding patches, which the transformer encoder processes. It does so in order to comprehend the image’s local and global characteristics. Last but not least, the ViT has a greater precision rate with less training time on a large dataset.
Have a project in mind that includes complex tech? Connect with us here to make your dream a reality!
Disclaimer: The opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Dexlock.



