Let's Discuss
Enquire NowAutomated Fact-Checking API based on Knowledge Base
Feb 21, 2023by, S.Sidharth
NLP
In today’s digital age, the abundance of information available online has created a significant challenge for many people: how to determine what information is reliable and accurate. This problem is especially acute for students, who need to conduct research and complete assignments that rely on accurate information. Many educational apps and platforms recently have started to claim that they have fact-checking systems incorporated to verify the accuracy of information presented to users, but its accuracy is a matter of concern.
Paperhack is designed to make the paper-writing process quick, easy, and stress-free. Whether you need to write a paper or an essay, Paperhack has you covered to produce high-quality work in no time.
The fact-checking system in paperhack is designed to analyze the content generated by the app, comparing it to a vast knowledge of verified information, and providing feedback to the user on any discrepancies or inaccuracies in the content. This helps improve the overall quality and accuracy of the content and also develops students’ critical thinking skills.
Let’s now dive into a brief analysis of the technical components of the fact-checking system, which includes examining the natural language processing techniques and deep learning algorithms implemented to scrutinize and authenticate the content.
Although the challenge of identifying fake information has been present for many years, most of them require users to manually evaluate the content, which can be time-consuming and labour-intensive. One such popular solution is Snopes. Google also has a fact-checking system. Google’s Fact Check Tool is a resource that is designed to help users identify whether a particular claim is true or false. However, while the tool is useful for general fact-checking, it may not be comprehensive or reliable enough to be used in academic areas, where a high degree of accuracy is crucial. This is, where our article-generating app, paperhack, with its integrated fact-checking system comes into play.
Our application utilizes the combination of FEVER(Fact Extraction and VERification), ISBN, and SnoMed Ct Dataset. FEVER comprises 185,445 claims that were generated by modifying sentences obtained from Wikipedia. The claims were subsequently classified by annotators as AGREES, DISAGREES, or CANNOT BE DETERMINED. To support the claims, we used hypotheses that are sentences extracted from the summary section of relevant articles. Unlike other datasets, FEVER represents a different problem formulation, requiring not only the classification of the relationship between two pieces of text but also linking a given claim to the corresponding evidence in a knowledge base, which in this case is a dump of Wikipedia. Therefore, the FEVER dataset is an essential validation for our research.
SYSTEM ARCHITECTURE
The fact-checking system architecture is divided into three main parts: the sentence selection model(level one), the candidate selection model(level two), and the classification model (level three). Our approach seeks to replicate the human fact-checking process.
- Model level one: The sentence selector: The generated article is divided into sentences. The first level model goes through these entire sentences and picks a sentence that a user would have selected to search for whether it’s fact or not. We have used a binary classifier trained over a custom-made dataset.
- Model level two. The Knowledge Base Search: The second-level model conducts a comprehensive search of the entire knowledge base by analyzing the full text. A NER-based approach along with Apache Lucene is here used for querying.
- Model level three. NLI Model: The NLI model presented is to use a Siamese network that utilizes a BERT-like model as a trainable encoder for sentences. A Siamese network is a type of neural network that is used for measuring the similarity between two different inputs, such as two sentences. By using a Siamese network with a BERT-like model as the encoder, the system can compare the claim to each candidate article by measuring the similarity between their encoded representations. This allows the system to determine which article(s) contain the most accurate information and provide this as evidence for the claim.
General Architecture

Figure 1: General architecture of the fact-checking system
General WorkFlow
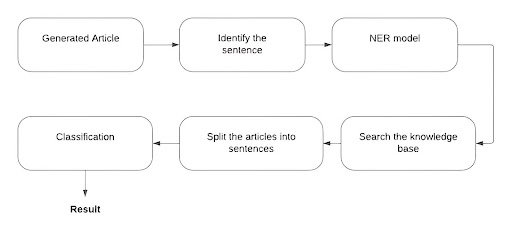
Figure 2: Full overview of the fact-check architecture
TRAINING & TESTING
The fact classification task utilized a Bart-base+fine tuned model, which achieved a 75.91% accuracy. Using an NVIDIA T4 GPU instance, the model was able to make a claim and generate a prediction in just approximately 5 seconds.
CONCLUSION
In conclusion, the fact-checking system integrated into our article-generating application has the potential to revolutionize the way students learn and research. By using state-of-the-art natural language processing techniques and machine learning algorithms, our system can effectively and efficiently verify the accuracy of information presented in academic papers, saving students time and improving the overall quality of their work. Our system’s unique use of a Siamese network and NLI model allows for a more nuanced analysis of text and better detection of false information. We have demonstrated the effectiveness of our approach in experiments and shown that it outperforms existing fact-checking solutions in terms of accuracy. In addition, our system has been designed with a focus on user experience, integrating seamlessly with our app and providing an intuitive interface for students to interact with. We believe that this fact-checking system has the potential to significantly improve the quality of academic work and help students become better critical thinkers and researchers. Check out our latest projects here.
Disclaimer: The opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Dexlock.



