Let's Discuss
Enquire NowConversion of NLP questions to graph query using NER
Mar 3, 2022by, Renjith R Kartha
NLP
Using Natural language to query a database
With the onset of the new decade, research in the field of data exploration has expanded multi-folds, with new approaches being suggested to better abstract the objects and detect patterns of importance. From conventional query language-based database systems to present-day natural language-dependent chatbots, the control over data has shifted from specialized developers to the common man, thus empowering the masses. Data is the oil of the 21st century, and along with this potential comes the challenging problem of effectively querying it. Research in the field of data mining has proposed several models of storing and accessing data at scale to derive conclusions about the system. Currently, existing systems have been using pattern matching, semantic grammar, and syntax-based methods to produce intermediate query representations.

Natural language interfaces to database systems produce database queries by translating natural language sentences into a structured format which in our case, is a subgraph query. They are starting to play an increasingly important role as people, not only people with specific domain expertise or knowledge of structured query languages, seek to obtain information from databases. These databases containing massive amounts of data are expanding rapidly because of a swift increase in text and voice interfaces as access to the web and mobile technologies for the common public has increased.
Different Approaches
The problem of data not being accessible to a lot of people, because of a lack of expertise, is not new. Several solutions were proposed to solve this problem. Let’s take a look at a few promising ones over time:
Symbolic or Rule-Based approach: Language knowledge is explicitly encoded in rules or other forms of representation. Information is extracted by analysing language at different levels. Linguistic functionality is obtained on the output by applying certain rules to it. The rule-based reasoning of human language allows us to do symbolic processing. Although this approach had worked for certain queries it was extremely rigid and not flexible enough to capture context or inflexions in grammar.
Corpus-Based Approach: A corpus is a collection of machine-readable text.
Corpora are primarily used as a source of information about the language and several techniques have emerged to enable the analysis of corpus data. Syntactic analysis is done based on statistical probabilities estimated from a training corpus. Lexical ambiguities are resolved by considering the likelihood of multiple interpretations based on context. Empirical NLP methods use statistical techniques like n-gram models, hidden Markov models (HMMs), and probabilistic context-free grammars (PCFGs).
Connectionist Approach (Using Neural Network): Since human language capabilities are based on neural networks in the brain, Artificial Neural Networks (also called connectionist network) provides an essential starting point for modelling language processing. The sub-symbolic neural network approach holds a lot of promise for modelling the cognitive foundations of language processing. The approach is based on distributed representations that correspond to statistical regularities in language instead of symbols.
Our Approach
The approach we will be discussing in this blog will involve elements of both corpora-based and rule-based approaches. Since our approach is rule-based to a certain extent it is necessary to define our use case specifically.
Use case: A natural language interface for graph databases.
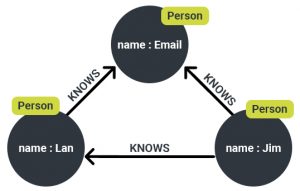
So there we have a definition, How do we go about solving the problem? Graph databases store relations between entities in the form of nodes and edges. Therefore we must find a way to resolve the sentences that we receive as input to nodes and edges.
Each node is an entity and these entities will be appearing in our query, hence if we resolve this entity to an existing node in our graph DB we are halfway to our solution
NER: Entities in these sentences can be identified using named entity recognition, each named entity eg: name of professor, country, class etc can be classified to the name of a node in the graph database.

But what about the next half? How do we resolve the relationship between the entities? This is required to find the edges that we’ll be traversing with our query.
Relation Extraction: After applying NER on the query, it passes through relation extraction, where we identify the relations between the entities in the sentences, each of these relations is already defined and classified into the categories of edges that exist in the graph DB that we are trying to query.
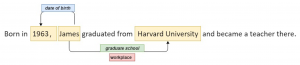
So after applying both these processes which are offered by NLP libraries like Spacy, Stanford NLP and MITIE, we will be able to develop an intermediate form , or a blueprint of the query which defines the node name and edges connecting the nodes, this form can be converted to graph query in corresponding graph query language with minimal code.

Disadvantages
- The system is too dependent on the use case and DB, i.e. what kind of information DB stores eg: university dd, employee details etc since NER is trained and nodes are classified and defined based on this information.
- Very lengthy queries cannot be parsed
Advantages
- Can achieve results with minimum training data.
- Multiple-use cases can be covered with fine-tuning.
Conclusion
Systems like the one discussed above aren’t the best with the current technologies available to us, e.g. neural networks have gone a long way in understanding context and relation between words in sentences but they need large amounts of data to be trained on, this is not available to us in the use case discussed above. Therefore this system serves best as a data generator, which can be tagged as right or wrong, to train neural networks which may be able to yield far more accurate results and generalises much better. If you have any projects regarding NLP we are here to help you out, connect here.
Disclaimer: The opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Dexlock.



