Let's Discuss
Enquire NowCrypto Forecasting Using Machine Learning
Jan 4, 2022by, Jishma
Machine Learning
First, let’s take a look at the cryptographic world. Cryptocurrencies have surged in popularity and volatility, resulting in big profits for investors (as well as losses). Thousands of cryptocurrencies have been created, with Bitcoin (BTC), Ether (ETH), and Dogecoin (DOGE) among the most well-known.
Cryptocurrencies are frequently traded across crypto exchanges, according to CryptoCompare, with an average daily volume of $41 billion transferred in the previous year (as of 25th July 2021).
The price movements of numerous cryptocurrencies are inextricably linked.
Bitcoin, for example, has historically been a major driver of cryptocurrency price fluctuations, but other coins also have an impact. In financial modelling, predicting how prices will behave in the near future is critical. We want to predict whether prices will rise or fall, and by how much, using historical price time series as training data, i.e. asset returns. Predicting how costs will behave in the near future is a crucial task in financial modelling. Using previous price time series as training data, we wish to predict whether prices will rise or fall and how much, i.e. asset returns.
The problem of estimating bitcoin profits is still open and challenging to solve. This is a fascinating issue domain for the ML community because of the extreme volatility of the assets, the non-stationary nature of the data, market and meme manipulation, asset correlation, and the extremely fast-changing market conditions.
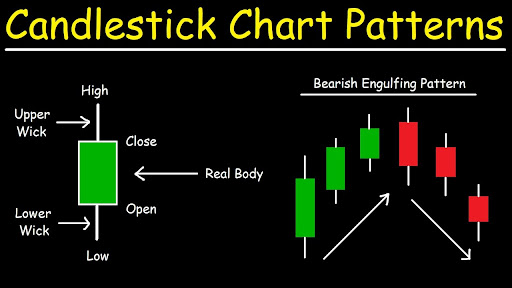
Candlestick charts
The trade data format is a compiled version of market data that includes the Open, High, Low, and Close. This information can be shown using the popular candlestick bar chart, which allows traders to do technical analysis on intraday numbers. The price range between the opening and closing of that day’s trade is represented by the body length of the bar. If the bar is red, it implies the close was lower than the open, and if it is green, it means the close was higher. Bullish and bearish candlesticks are terms used to describe these types of candlesticks. The high and low prices of that interval’s trade are represented by the wicks above and below the bars.
Cryptocurrency price forecasting is critical for investors. The Light Gradient Boosting Machine (LightGBM) is used to forecast the cryptocurrency market’s price trend (falling or not falling). We combine daily data from 42 different leading cryptocurrencies with critical economic metrics in order to use market data. The LightGBM model outperforms the other techniques in terms of robustness, and the overall strength of the cryptocurrencies has an impact on forecasting performance.
This can successfully advise investors in the creation of a suitable bitcoin portfolio while also mitigating risks. With the addition of more tree nodes, the total training time for LightGBM grows. LightGBM includes numerous settings for controlling the number of nodes per tree.
LightGBM Advantages
- Faster training speed and higher efficiency
- Lower memory usage
- Better accuracy
- Support of parallel and GPU learning
- Capable of handling large-scale data
Parameter tuning
The suggestions below will speed up training but might hurt training accuracy.
- Reduce max depth: This is an integer that determines the maximum distance between a tree’s root node and a leaf node. Reduce max depth to save time during training.
- Decrease num_leaves: Regardless of depth, LightGBM adds nodes to trees based on the gain from adding that node.
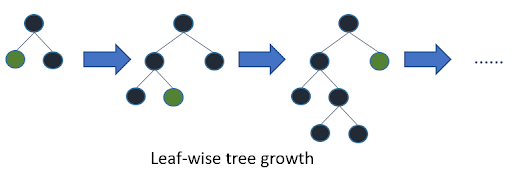
- Increase main gain to split: LightGBM chooses the split point with the biggest gain when adding a new tree node. The reduction in training loss that occurs as a result of introducing a split point is known as gain. Increase main gain to split to reduce training time. LightGBM sets the main gain to split to 0.0 by default, which indicates “there is no improvement that is too modest.”
- Increase min_data_in_leaf: The number of observations that must fall into a tree node in order for it to be added is the minimum.
- Increase min_sum_hessian_in_leaf: For observations in a leaf, the minimum sum of the Hessian (second derivative of the objective function assessed for each observation)This is simply the minimal number of records that must fall into each node for particular regression aims.
- Decrease num_iterations: The num _ iterations argument determines how many rounds of boosting will be performed. This can alternatively be regarded as the “number of trees” because LightGBM employs decision trees as learners. Reduce the number of iterations to save time during training.
- If early stopping is enabled, the model’s training accuracy is tested against a validation set that incorporates data not available during the training process after each boosting round. The accuracy of the current boosting round is then compared to the accuracy of the previous boosting round.LightGBM will end the training process if the model’s accuracy does not increase for a certain amount of rounds.
-
Decrease max_bin or max_bin_by_feature When Creating Dataset: LightGBM training buckets have a continuous feature that divides them into discrete bins, allowing you to train faster and with less memory. This binning is done only once during the Dataset creation process.
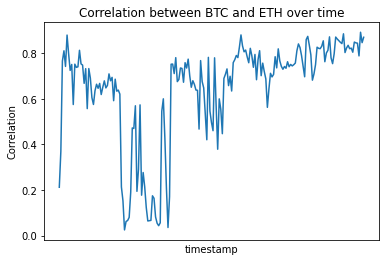
It’s worth noting that the assets have a high yet erratic correlation.
We can see that the dynamics are changing over time, which is important for this time series task, which is how to forecast in a very non-stationary environment. Non-changing statistical features over time, such as the mean, variance, and autocorrelation, characterize a system’s or process’s stationary nature.
Non-stationary behaviour, on the other hand, is defined by a continuous change in statistical parameters across time. Stationarity is significant since it is required by many valuable analytical tools, statistical tests, and models.
Although there are some clear ways in which AI/ML will affect the next generation of crypto assets and infrastructure, there are also less evident ways in which crypto can influence AI/ML technology. Decentralized AI is a new technology trend that claims to alleviate some of AI’s increasing centralization concerns by utilising decentralised computation and tokenization approaches. A subdomain of the broad decentralised AI scheme is mechanisms that use crypto assets to construct economies in which firms and individuals are prohibited from publishing data and AI/ML models. The electricity that powers AI and machine learning is data, but it is primarily monopolised by a few incumbents, and there are no incentives for enterprises to collaborate and share their findings in order to break the monopolistic loop.
Implementing creative and rewarding procedures could assist businesses in establishing channels for regular participation in the design and execution of AI/ML models for specific tasks, with the advantages shared. Another popular problem in AI/ML these days is bias and fairness, which could be greatly influenced by the adoption of native crypto technology.
Disclaimer: The opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Dexlock.



