Let's Discuss
Enquire NowML in Production Inference Speed & Scaling
Aug 17, 2022by, Renjith R Kartha
Machine Learning
The latest machine learning models, including deep learning models, are capable of achieving state-of-the-art results for several ML tasks. Their capability is seeping into places that were previously not considered under the realm of ML.
Each passing generation of Deep Learning Neural Network models shows compromising results on several benchmarks.
Imagine we need to create or maybe fine-tune an existing model for a task, we have an impeccable data science team, who has managed to obtain high accuracy, and precision. There is a catch though if the model predictions are not fast enough, will it benefit the end user, you want your phone to recognise your face in milliseconds,s not even seconds, if it stretches to minutes then why have this feature at all, I would rather type the passcode and unlock my phone.

So speed is important in production, inference speed to be specific. And while you strive for a better inference speed you cannot let the prediction’s accuracy suffer much. Since we know that it is important to strike a balance between these, we now have a clear understanding of what we need in production, a model capable of delivering high accuracy and satisfactory inference speed.
Since now we have an idea of what must be achieved, let’s take a look at the challenges. So be ready to delve into some technicalities.
Challenges:
- Most modern deep learning models like Bert, GPT, and T5 are large Deep Learning Neural Networks and are capable of giving high accuracy but at the cost of speed.
- Models need to run on edge devices, which won’t be able to host large models.
- A large amount of data units will need to be processed since a large number of requests are received in production, hence the model will need high throughput.
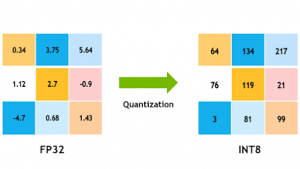
Quantisation
Large models have a lot of weights, remember that these weights are floating point numbers, and occupy 32 bits memory size so if we represent them using integers (8bits) it’s possible to reduce the size of the model significantly.
This increases the inference speed and also lets the model be loaded using a much lesser amount of memory.
Quantization is natively supported in Tensorflow. Models in Pytorch will have to be converted to one runtime or Nividia TensorRT
Using A Different Model
We might have chosen a model by observing its performance on benchmark tasks. Our eye for accuracy and precision might have misled us to a base model which required a minimum amount of fine-tuning and got great results.
If quantisation is not cutting it then we might have to switch to a much smaller base model and retrain it, this might require larger amounts of high-quality data.
Scaling
Multiple instances of the model can be spawned to handle a lot of requests while in production. This cannot be done in edge devices but for use cases where the model is hosted on a server. Tasks like machine translation and content generation etc can use this method. The inference can either be real-time for use cases like instant content generation and translation, for purposes like Data Analytics a method called batch inference is done, where a large amount of data accumulated over a time period is input into the model as a batch.
Scaling increases the throughput of the service, hence allowing a larger number of users to engage with a web app or mobile app concurrently.
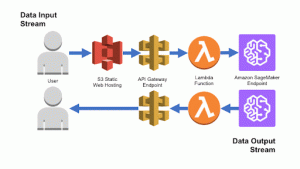
There are multiple ways to make this happen. One of the pre-packaged solutions offered by AWS is AWS sagemaker
AWS sagemaker
Why trouble yourself by reinventing the wheel? If there is an out-of-the-box solution, you could save weeks of effort by using a fully managed service rather than building something from scratch, but be sure it’s not hard on your wallet.
If it doesn’t provide the solution you’re looking for then it’s time to roll up your sleeves and get to work. AWS offers some Machine Learning Products Sagemaker is one such product It is a fully managed service that we require.
Sagemaker allows us to train and deploy models at scale.
It offers a jupyter notebook-like interface for training, hence you can upload your local notebook and start off using large models which would not have been possible on your laptop.
Sagemaker provides a fully managed service for your model. It automatically monitors and scales the cloud infrastructure according to traffic in sagemaker inference endpoints.
As I said in the beginning if you don’t get your desired result or Sagemaker is too hard on your wallet there are other solutions you can try out.
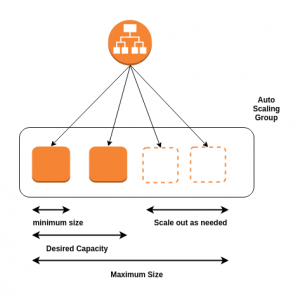
Autoscaling Group
Server platforms offered by AWS can be used for scaling.
You can use an AWS autoscaling group for your inference service. A load balancer distributes the requests across the instances.
Containerising your inference service will make it easier for you to scale up and down as you don’t have to be concerned about the environment anymore. This makes it easier to shift between instances and update the model.
Depending on how your model consumes the input you might have to write a custom scaling configuration. Eg a job que , requests, Stack size etc.
This should be a much more economical solution if you could not find the service or customizations you were looking for on Sagemaker. But there’s the responsibility of managing certain things by ourselves, like the scaling configuration, deployment scripts etc..
If you have any queries regarding ML, our team is here to help you out, click here to know more.
Disclaimer: The opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Dexlock.



