Let's Discuss
Enquire NowRedshift vs Snowflake – The Better Data Warehouse
Nov 15, 2022by, Maheswari C.S
Technology
Data is money. The big data market is predicted to reach 103 billion US dollars by 2027, with the software industry dominating the market with a 45 percent stake. With enterprises acquiring more data per day which is needed for storage and analytics, it is equally important to choose a data warehouse that can handle these huge volumes of data with ease. Moreover, an excellent warehouse helps its users with integrations, accessibility, and security.
Amazon Redshift and Snowflake are two of the most popular data warehouses in the game at present. So how will you determine which one you should take on your team? To answer that, let us see their main differences.
![]()

Data Security
Amazon Redshift offers end-to-end encryption that can be tailored specifically to meet your security needs. It gives access control, cluster encryption, security groups, sign-in credentials, SSL connections, and VPC/VPN capabilities to manage additional security features and tools without additional charges.
Snowflake, on the other hand, has data encryption and VPC/VPN network isolating options. The security and compliance capabilities offered by this warehouse are tailored to each edition. This in turn makes it easier for the user to choose the amount of security that is most suited to their data strategy.
Performance
Amazon Redshift and Snowflake behave differently due to their respective designs, which makes it challenging to compare their performance. Both Redshift and Snowflake use massively parallel processing (MPP) and columnar storage to run multiple computations at once, enabling advanced analytics and reducing the time required for large operations.
They also offer concurrent scalability, but Amazon Redshift has machine learning capabilities. Although its initial query time could be a little longer, the query compile cache speeds up subsequent searches. Additionally, a range of options for standardizing searches and data types are available on this platform. Redshift’s ATO (Automatic Table Optimizations) can be used to automatically regulate the SORTKEY and DISTKEY to optimize queries and deliver a significant reduction in execution time for queries involving JOIN and WHERE. Users can also manually modify these settings in some cases.
When it comes to the runtime of unoptimized queries, Snowflake clearly takes the lead. Its distinct architecture can handle both structured and semistructured data. For optimizing their autonomous performance, Snowflake maintains computation, storage, and cloud services distinctively.
Computation and Storage
Snowflake’s separation of storage and computation functions allows users to scale these services independently. With the addition of R3 nodes, Redshift creates a scaling environment by offering users the ability to scale computing independently of storage. However, when it comes to JSON storage, Redshift’s support for it is far less comprehensive than Snowflake’s. Snowflake’s native, built-in methods can be used to query and store JSON. JSON, when loaded into Redshift, is broken into strings which makes it more challenging.
Redshift Spectrum enables the execution of SQL queries directly on the data in the S3 bucket, preventing data movements. Amazon Redshift Managed Storage comes with AQUA (Advanced Query Accelerator) capabilities when using RA3 nodes at no extra charge. AQUA, a distributed and hardware-accelerated cache, speeds up specific sorts of queries so that Amazon Redshift can operate up to 10 times quicker than other cloud data warehouses.
Price and Maintenance
Snowflake separates compute usage from storage and automatically provides concurrency scaling. The price of Snowflake mainly depends on the edition chosen by the user. There are a total of five editions, with added functionality associated with each increasing price level, so users skip the features that are not needed. The editions are based on data type, volume, geographic location, and the platform (AWS or Azure). When it comes to maintenance, Snowflake automates maintenance for greater tasks. It reduces the amount of time needed for identifying the problem and resolving it.
Amazon Redshift gives users a set daily concurrent scaling allowance and charges per second after usage surpasses it. Redshift offers the chance for significant long-term savings if you sign a one- or three-year contract. Users can choose to pay by the number of bytes scanned every hour or by the type of nodes in each cluster. However, Redshift needs more manual maintenance to perform a wider range of non-automated operations, like data vacuuming and compression.
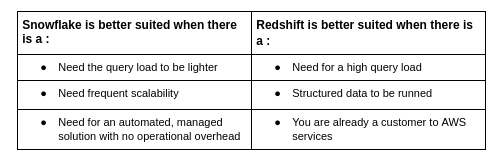
When to use what?
How can Dexlock help?
We at Dexlock make it our priority to present our clients with the topmost Business Intelligence tools. Our team of competent professionals work with next-generation technologies to give our clients the best service possible. If you have any projects regarding the above, contact us.
Disclaimer: The opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Dexlock.



