Let's Discuss
Enquire NowYOLO: Enhancing Object Detection Models
May 3, 2023by, Maheswari C.S
Technology
Remember the Bee Movie? Yeah, it’s pretty inaccurate. But it did reinstate that bees are important to the ecosystem. There are countless precautionary and conservative measures implemented to get the bee population thriving. But what’s new for AI in keeping the bees happy?
When tasked with developing a system that cultivates data from live footage into useful statistics for studying bees, Caleb Cheng sought the help of YOLOv4, an object detection framework.
Unfortunately, this article isn’t about the system he created. You can read all about it here. This article is rather about the technology behind it – YOLO.
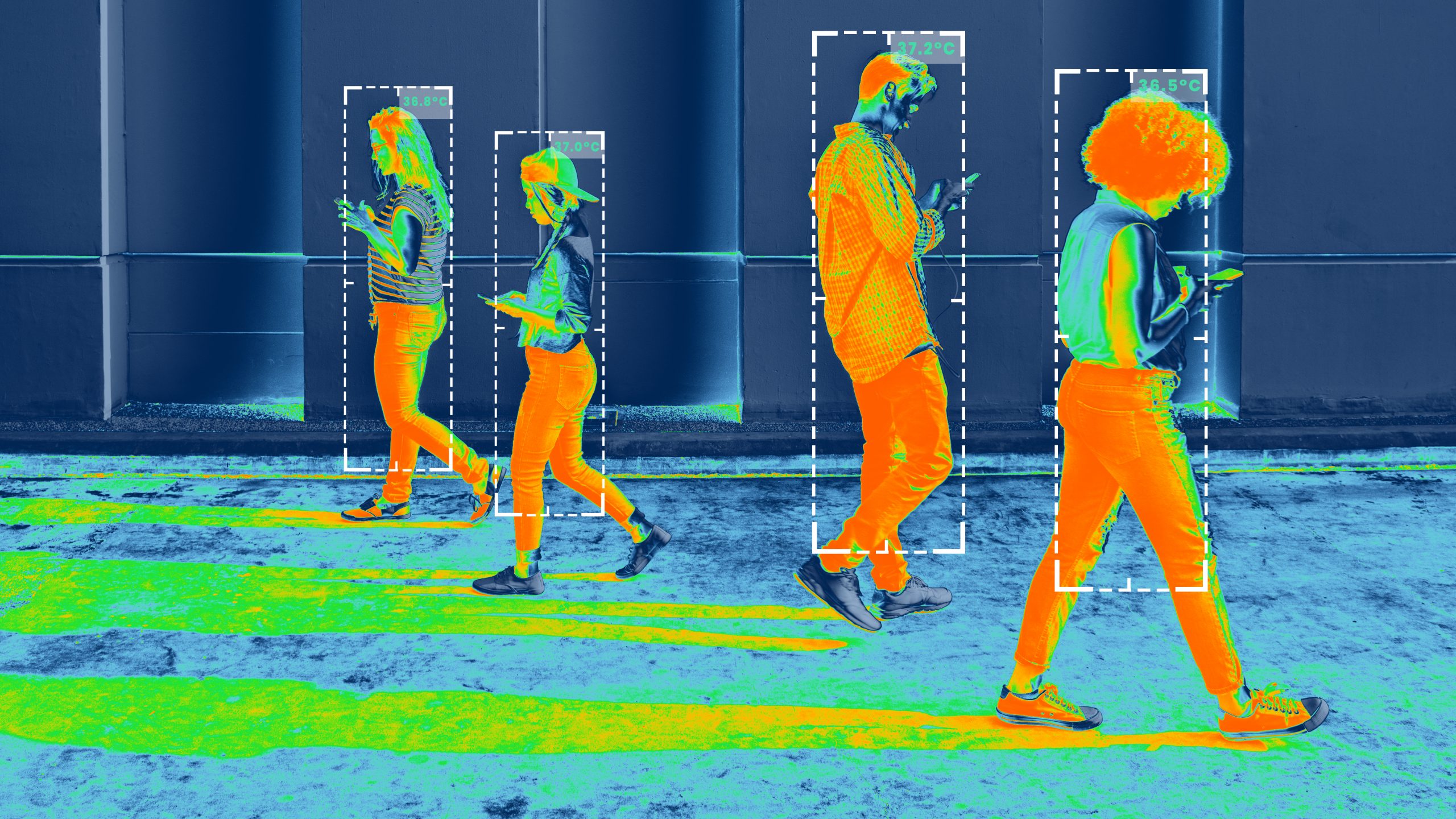
A brief introduction to YOLO
YOLO or You Only Look Once is a state-of-the-art object detection framework that identifies multiple objects in a single frame as a regression problem and provides the class probabilities of the detected images. Real-time object detection is performed by this algorithm through convolutional neural networks (CNN) and requires only a single forward propagation to detect objects.
The distinctive factor that sets all YOLO algorithms apart from other object detection models lies in their speed, precision, and learning capabilities. YOLO has a highly responsive architecture. The base YOLO model processes images in real-time at a frame rate of 45 frames per second. While it has a higher localization error rate than improved detection systems, it is much less prone to forecast false positives. Over the years, YOLO has advanced with different versions for optimal object detection.
- YOLOv1 was the first end-to-end differentiable object detection network, combining the bounding box drawing and class label identification problems.
- YOLOv2 came with incremental enhancements such as BatchNorm, greater resolution, and anchor boxes.
- YOLOv3 was miles ahead in terms of accuracy, speed, and architecture. For instance, while YOLOv2 used Darknet-19 with 19 convolutional layers as its backbone feature extractor, YOLOv3 employed Darknet-53 with 53 convolutional layers making it more powerful.
- YOLOv4 was made to be trained on a single GPU to significantly increase the inference time required.
- YOLOv5 is an open-source project that contains a series of object identification models and detection techniques based on the YOLO model pre-trained on the COCO dataset.
- The latest YOLACT or You Only Look At Coefficients, is based on the segmentation of instances in real time.
YOLO architecture and mechanism

The YOLO algorithm divides the image detected into N grids, each with an equal-sized SxS region. Each of these N grids is in charge of finding and locating the object they contain. Accordingly, they also forecast the object label, the likelihood that the object will be present in the cell, and the bounding box relative to their cell coordinates. However, cells may also predict the same thing with different bounding boxes thus generating a lot of duplicate predictions.
To address this problem, YOLO uses Non-Maximal Suppression which looks at the likelihood scores connected to each choice and selects the largest one. After this, the bounding boxes with the highest Intersection over Union (a phenomenon that describes how boxes overlap) are suppressed. Up until the final bounding boxes are obtained, this process is repeated.
Limitations of YOLO
Since each grid is only able to detect one object, YOLO has trouble identifying and classifying small things in images that are naturally grouped together, for example, rice grains. Even though it provides improved object detection results, YOLO also has lesser accuracy when compared to significantly slower object identification techniques like Fast R-CNN.
Conclusion
YOLO and its various versions provide a reliable, speedy method of object detection. In addition, the algorithm comes with excellent learning capabilities which helps it to learn about object representations. One of the main fields where the YOLO algorithm can be applied in autonomous cars. Another likely application lies in security systems to identify threats or trespassers. YOLO can also contribute majorly to wildlife detection and conservation.
Have a project in mind that includes complex object detection frameworks? Connect with us here to make your dreams a reality!
Disclaimer: The opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Dexlock.



