Let's Discuss
Enquire NowBidirectional NER modelling for text generation
Apr 18, 2022by, Alfas Hakeem P
NLP
The Text Generation is a Natural Language Processing task that involves automatically generating meaningful texts. Named Entity Recognition(NER) is an important Natural Language Processing technique that recognizes and extracts specific types of entities in a text such as names of people,country,job titles, sports names etc.
LSTM (Long Short-Term Memory) architecture is very good for analyzing sequences of values and predicting the next one. For example, consider the sentence “The driver stopped the car suddenly”.
First, the whole corpus of sentences is joined. Then every word is tokenized, that is, assigned a particular number, and n-gram sequences are made from it as follows:
 So, this sentence required 6 sequences. Similarly, it is repeated for all the other sentences in the corpus. The next step is to find the sequence with the maximum length, and every other sequence will be padded upto that maximum length. The last word of each sequence will be considered as a ‘label’, in order to predict this last word from the previous word given a seed sequence.
So, this sentence required 6 sequences. Similarly, it is repeated for all the other sentences in the corpus. The next step is to find the sequence with the maximum length, and every other sequence will be padded upto that maximum length. The last word of each sequence will be considered as a ‘label’, in order to predict this last word from the previous word given a seed sequence.
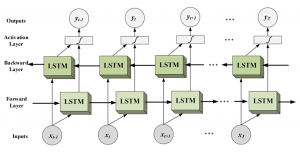 Now a bidirectional LSTM can be used to train two sides, that is, while predicting a word it will take into consideration the context of the previous word as well as the word after it. This helps the model to learn quicker and produce more meaningful outputs.
Now a bidirectional LSTM can be used to train two sides, that is, while predicting a word it will take into consideration the context of the previous word as well as the word after it. This helps the model to learn quicker and produce more meaningful outputs.
We use a Sequential model API upon which the various operations on layers are performed. After applying the bidirectional LSTM, a dropout layer is added to avoid overfitting, one more LSTM layer and a denserlayer with ReLU(Rectifier Linear Unit) activation function and a regularizer to avoid overfitting is added.The output layer has “softmax” so as to get the probability of the word to be predicted next. The loss is set to “categorical_crossentropy” with optimizer “adam”.
Depending on the input length, the model will produce a text with that many number of words, and its accuracy or meaningfulness of the text will depend on the number of words as well as the type of words given in the corpus. If you would like to know more about our resources regarding bidirectional ner modelling, click here.
Disclaimer: The opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Dexlock.



