Let's Discuss
Enquire NowWhat is IPFS and how to integrate it with Ethereum?
Jul 12, 2022by, Aswin S Kumar
Block Chain
Large volumes of data can be exceedingly expensive to store on a blockchain mainnet like Ethereum, with surveys estimating that it might cost more than $50,000 USD per GB of storage. A different option is to store data off the chain and refer to it with a unique identifier. However, data referenced by these identifiers are mutable, posing substantial hurdles to blockchain’s openness and immutability. Let’s see how decentralized storage technologies like IPFS can overcome this.
IPFS
The InterPlanetary File System (IPFS) is a peer-to-peer (p2p) storage network that lets users host content and share it with peers all over the world.
The majority of today’s storage options are centralized. Assume you have access to a cloud service provider that allows you to upload files and access them via a URL. But what happens if the cloud service provider is unavailable? Are you going to be able to open the file? What if Wikipedia’s servers went down when you were looking for important information? This is the issue that centralization has created.
IPFS is a distributed system for storing and accessing data in its most basic form. IPFS creates hashes for the data you submit and allows you to access it using those hashes. As an answer to the prior question, what if Wikipedia servers go down while you’re looking for important information? There’s an IPFS-based mirror of Wikipedia that you could utilize instead.
ipfs.io/ipfs/QmXoypizjW3WknFiJnKLwHCnL72vedxjQkDDP1mXWo6uco – Wikimedia Commons on IPFS
IPFS is based on the three principles listed below.
- Content addressing
- Directed acyclic graphs (DAGs)
- Distributed hash tables (DHTs)
Let’s take a look at each one of them.
Content addressing
IPFS allows you to search for information based on its contents rather than its location. This is made possible by pointing a Content Identifier(CID) to every material on the IPFS ecosystem. Content addressing allows us to validate the integrity of data by hashing the content we received and comparing it to the CID of the material we asked for, thanks to content addressing.
“CIDs aren’t just hashes of files” – The CIDs utilized by IPFS to retrieve content aren’t just hashes of files. It also includes information such as the name of the hashing algorithm and the number of bits used.
If you’re looking for a file with the CID QmaWbv93oMmLLhHSL2QKLfHPRhvH5in59e59TJN1Fv3oJA and the server responds with abcx.jpeg, go to CID inspector provider by IPFS and append the CID to the end https://cid.ipfs.io/#QmaWbv93oMmLLhHSL2QKLfHPRhvH5in59e59TJN1Fv3oJA

Then, under the DIGEST (HEX) section, copy the file’s hash and run the following command to verify that the file matches the hash.
echo “0E7071C59DF3B9454D1D18A15270AA36D54F89606A576DC621757AFD44AD1D2E “abcx.jpeg” | shasum -a 256 —check 

Directed acyclic graphs (DAGs)
When a file is added to IPFS, it is divided into chunks, each of which is represented by a node with its own unique identity. These nodes are connected by the use of a data structure known as directed acyclic graphs. IPFS employs Merkle DAGs, with each node having a unique identifier (CID) that is a hash of the node’s contents and the identifiers of its children. The creation of DAG can be visualized here:
https://dag.ipfs.io/
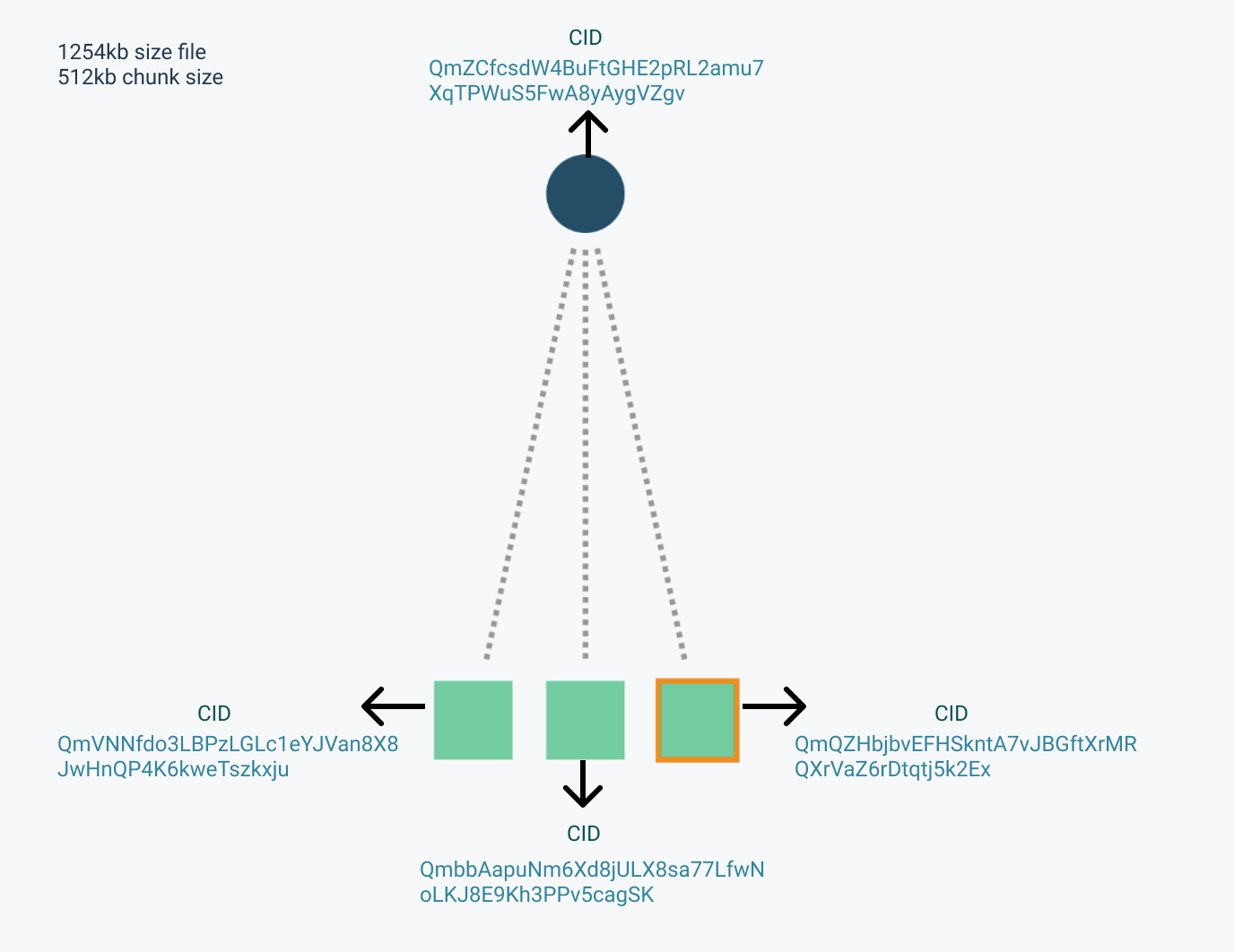 Figure2. DAG formation by IPFS
Figure2. DAG formation by IPFS
When a file is split into pieces, distinct sections of the file can come from various sources. If a file with a size of 1024 kb is added to IPFS with a chunk size of 256 kb, the file will be split into four chunks. Each chunk will be issued a CID and will form a leaf node in the DAG. The node’s CIDs will then be used to construct the parent node’s CID. The parent node’s CID, or the root hash, can be used to uniquely identify content in the IPFS ecosystem.
Now that you know IPFS generates CIDs to content and link that content together in a Merkle DAG, let’s see how it is retrieved.
Distributed hash tables (DHTs)
To find peers who host the content you’re looking for, IPFS uses distributed hash tables (DHTs), which are distributed systems for mapping keys to values.
When you request a file, IPFS looks up the peers who are storing the blocks of content you’re looking for. IPFS uses DHT again to determine the current location of peers once their identities have been discovered. Once the current location has been determined, IPFS connects to those peers using the Bitswap module and retrieves material by transmitting the CID of the blocks you want.
Uploading Files to IPFS
Let’s look at how to upload files to IPFS, retrieve the CID, and store it on the Ethereum blockchain.
To upload files to IPFS, you must first join the network by installing an IPFS node on your computer. An IPFS gateway can also be used to do this. For this tutorial, we’ll use the IPFS Infura gateway.
Index.js
// install ipfs-http-client dependency using npm install ipfs-http-client and import it.
import { create } from ‘ipfs-http-client’
// creating an ipfs client which connects to Infura API
const ipfs = create({ host: ‘ipfs.infura.io’, port: 5001’, protocol: ‘https’ })
// Add content to IPFS , and store the CID
const { cid } = await client.add(‘Hello world!’)
That’s it. This CID can be stored on the Ethereum blockchain as part of any transaction that satisfies your use case.
Thus by the use of distributed hash tables, DAGs and content addressing IPFS provides decentralized storage, which can be used as the primary way to store data of the chain without sacrificing the openness concept of blockchain.If you would like to know more about how we can provide you services regarding IPFS, click here.
Disclaimer: The opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Dexlock.



