Let's Discuss
Enquire NowDeep Sort: An insight into object tracking
Sep 14, 2022by, Pooja Ramesh
Artificial Intelligence
While I, like you, loathe getting pulled over by officials, I can’t really deny that having cameras attached to traffic lights that can track and count passing vehicles could well be useful to society.
Every day, computers enhance their capacity to think, evaluate circumstances, and implement choices in the very same way that humans do. Understanding vision is key to making advancements in the development of AI technology. One of the things that scientists and engineers have struggled with is how to get our systems to see things not pixel by pixel, but rather the overarching patterns in a picture or video. Object recognition and tracking technology have come a long way in that regard, and the boundaries are being challenged and extended just as we speak.
While the scientific community has concentrated on detecting objects in images, tracking objects in video is a lesser-known but extensively used area that requires us to incorporate our knowledge of detecting objects in static images with the interpretation of temporal information and the use of it to best predict trajectories. Tracking sporting activities, capturing burglars, automating speeding charges, or, if your life is a little more miserable, warning yourself when your three-year-old dashes out the door without assistance are all possibilities.
Single object tracking
Single object tracking is probably the most well-known and basic of the tracking sub-problems. The aim is to simply lock on to a particular object in an image and monitor it until it exits the frame. This type of tracking is faster and the more complicated issue of detecting this entity from others isn’t addressed.
Multiple object tracking

We are intended to latch onto every single object in the frame, uniquely identify each of them, and track those until they leave the frame in this type of tracking.
Object detection vs Object Tracking
With all of the jargon surrounding deep learning nowadays, terms and their meanings tend to become tangled up, causing a new learner a lot of confusion. So, what exactly is the distinction between “Object Detection” and “Object Tracking”?
Identifying an entity in a frame, putting a bounding box or an overlay around it, and classifying the object are all part of object detection. It’s important to note that the detector’s job is done here. It examines each frame separately and discovers a large number of things in that frame.
An object tracker, on either end, should now follow a particular object throughout the film. If the detector detects three cars in the frame, the object tracker must differentiate between the three sightings and track them over subsequent frames which uses a unique id. The tracker will need to use Spatio-temporal features because of this.
Challenges
It may appear that monitoring an entity on a straight stretch or in a clear location is simple. However, very few real-world applications are that simple and without obstacles. Here are some frequent issues that may arise while implementing an object tracker.
Occlusion

One of the most common barriers to perfect object tracking is an occlusion in media. As you can see, the man in the background is identified in the top figure (left), but the same man is unidentified in the next frame (right). The tracker’s duty now is to recognise the same person when he is detected in a later frame and match his prior track and features with his direction.
Variations in viewpoints
The purpose of tracking is usually to detect an object across multiple camera angles. As a result, we will be seeing substantial improvements in how we interpret the subject.
Non-stationary camera
When the camera used to track a certain object is also moving in relation to the object, unforeseen effects can occur.
Many trackers use an object’s features to keep track of it. In instances where the item appears to be different due to camera motion, such a tracker may fail. A reliable tracker for this problem could be extremely useful in applications such as object-tracking drones and autonomous navigation.
Annotating training data
Getting good training data for a specific scenario is one of the most frustrating aspects of constructing an object tracker. We need video sequences where each instance of the object is identified throughout, for each frame, unlike developing a dataset for an object detector, where randomly unconnected photos where the object is visible can be annotated.
Traditional Methods
- Meanshift
Meanshift, often known as mode seeking, is a prominent approach for clustering and other unsupervised issues. It’s similar to K-Means, but instead of using the simple centroid method to calculate cluster centres, it uses a weighted average that prioritizes points closer to the mean. The algorithm’s purpose is to locate all modes in a given data distribution. In addition, unlike K-Means, this technique does not require an optimal “K” value.
Let’s say we have a detector for an object in the frame and we want to extract some features from it. Users can get a basic picture of where the mode of the distribution of features is in the current state by using the meanshift technique. When we go to the following frame, where the distribution has changed due to the item moving about in the frame, the meanshift algorithm seeks for the new greatest mode and therefore tracks the object.
- Optical flow
This method varies from the previous two in that it does not require the usage of characteristics derived from the target object. Instead, the object is monitored at the pixel level using Spatio-temporal picture brightness fluctuations.
The goal of this section is to acquire a displacement vector for the object that will be monitored across frames. Optical flow tracking is composed of three main assumptions:
- Brightness consistency: Although the location of a tiny region may fluctuate, the brightness around it is believed to remain fairly constant.
- Spatial coherence: Neighboring points in a scene usually belong to the same surface, therefore their motions are similar.
- Temporal persistence: A patch’s motion changes gradually.
- Limited motion: Points move only a short distance and in a haphazard manner.
We apply the Lucas-Kanade method to construct an equation for the velocity of particular spots to be tracked once these requirements have been met (usually these are easily detected features). A given object can be followed throughout the film using the equation and various prediction techniques.
Kalman Filters
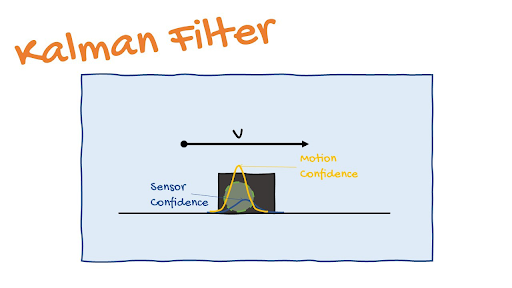
The “Kalman Filter” is the go-to algorithm in practically any engineering problem that includes prediction in a temporal or time series sense, be it computer vision, guidance, navigation, or even economics.
The basic idea behind a Kalman filter is to use existing detections and prior predictions to come up with the best guess of the present state while minimizing mistakes.
Assume we have a reasonably good object detector that can detect an automobile in our situation. However, it is not very accurate, and it occasionally misses detections, say 1 out of every 10 frames. Assume a “Constant velocity model” to efficiently track and predict the car’s next condition. Now that we’ve specified the simple model according to physical principles, we can make a good guess as to where the car will be in the next frame based on the presence detection. In an ideal world, everything sounds perfect. However, as I already stated, there is always a noise component.
Deep Sort Algorithm
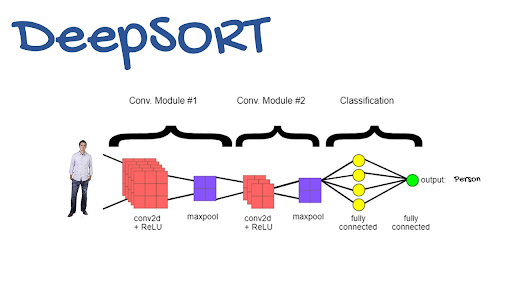
The deep sort algorithm is one of my favourites. It’s incredibly simple. One important item missing from all of the foregoing arithmetic is a visual comprehension of the bounding box, which we humans use all the time in tracking. We track not just distance and velocity, but also the person’s appearance. Deep sort enables us to add this feature by computing deep features for each bounding box and factoring in the tracking algorithm based on deep feature similarity. If you would like to know more about the various object-tracking processes, you could reach out to us here.
Disclaimer: The opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Dexlock.



