Let's Discuss
Enquire NowUsing the neural network for fake document generation
May 9, 2022by, Akshara B
Data Science
Artificial Neural Network is a group of interconnected neurons that mimics as a human brain. Recurrent neural networks(RNN) is a type of neural network which captures sequential data from the input. Sequential data is an interdependent stream of data, examples like time series data, language translation etc.
In RNN, it takes both input and previous values, for example, in a language translation, we have to know what is the current word and previous word to predict the next word. It can be used for generative models as well as Predictive models (making predictions). RNN’s can learn the sequence of a problem and then generate entirely new sequences for the problem domain.
Lets create a generative model for patient records in a hospital using RNN.
The most basic thing that we need to create a Predictive/Generative model is a Dataset. The output of the model or the sequences that the model generates will be dependent on the dataset we provide. The more data that is available, increases the overall generation throughput.
Here we are using a dataset with patient records that includes their MRN, SSN and other sensitive information. So our model should create a similar document as our second stage output.
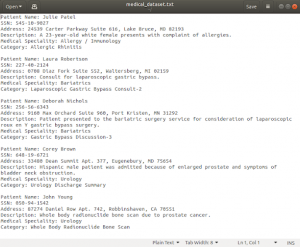
A small part of the dataset that we used is in the image above.
The IDE that we are going to use through this entire post is PyCharm.
- Develop LSTM Recurrent neural network for training generative model.
– Import the classes and functions that we considered to use to train our model.
import numpy from keras.models import Sequential from keras.layers import Dense from keras.layers import Dropout from keras.layers import LSTM,Flatten from keras.callbacks import ModelCheckpoint from keras.utils import np_utils from tensorflow.keras.utils import to_categorical
Then, to decrease the vocabulary that the network must learn, load the ASCII text for the dataset into memory and convert all the characters to lowercase.
filename = "../input/alice-wonderland-dataset/alice_in_wonderland.txt" raw_text = open(filename).read() raw_text = raw_text.lower()
– Next prepare the data for modelling by the neural network. For that we need to convert all the characters to integer
chars = sorted(list(set(raw_text))) char_to_int = dict((c, i) for i, c in enumerate(chars))
– The data has been loaded and we can now summarize the dataset
# summarize the loaded data
n_chars = len(raw_text)
n_vocab = len(chars)
print("Total Characters: ", n_chars)
print("Total Vocab: ", n_vocab)
Based on our requirement, we can define the training data for the network. and we have the flexibility to choose how to break up the text and how to expose it to the network during training.
We will split the text into subsequences with a fixed length, here an arbitrary length of 100 characters. We could easily split the data up by sentences and combine the shorter sequences and truncate the longer ones.
Each training pattern of the network consists of 100-time steps of one character (X) followed by one character output (y). While generating these sequences, we slide this window along the whole data, one character at a time, by allowing each character a chance to learn from the 100 characters that came before it (except the first 100 characters).
# prepare the dataset of input to output pairs encoded as integers
seq_length = 100
dataX = []
dataY = []
for i in range(0, n_chars - seq_length, 1):
seq_in = raw_text[i:i + seq_length]
seq_out = raw_text[i + seq_length]
dataX.append([char_to_int[char] for char in seq_in])
dataY.append(char_to_int[seq_out])
n_patterns = len(dataX)
print("Total Patterns: ", n_patterns)
Here we are defining a single hidden LSTM layer with 256 memory units. The network uses dropout with a probability of 20, the output is a Dense layer using the softmax activation function, which outputs a probability prediction for each of the 47 characters between 0 to 1.
The problem is a single character classification problem with 47 classes and as such is defined as optimizing the log loss (cross entropy), here we are using the ADAM optimization algorithm for speed.
# define the LSTM model model = Sequential() model.add(LSTM(256, input_shape=(X.shape[1], X.shape[2]))) model.add(Dropout(0.2)) model.add(Dense(y.shape[1], activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam')
We are actually modelling the dataset to learn the probability of each character in a sequence.
We are not building the most accurate model of the training data dataset which would predict each character in the dataset perfectly. We are building a generalisation of the dataset that minimizes the loss function.The network is very slow to train, so we will keep checkpoints for the entire training.
We can try to improve the quality of the generated text by creating a much larger network. For example add a second layer and keep the number of memory units at 500.
#define model model = Sequential() model.add(LSTM(500, input_shape=(X. shape[1], X.shape[2]), return_sequences True)) model.add(Dropout(0.2)) model.add(Flatten()) model.add(Dense(500)) model.add(Dropout(0.2)) model.add(Dense(y.shape[1], activation='softmax')) model.compile(loss='categorical crossentropy', optimizer='adam')
The model can now be fitted to the data. Here we use a large batch size of 128 patterns and a minimal number of 30 epochs.
# define the checkpoint
filepath="weights-improvement1-{epoch:02d}-{loss:.4f}.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='loss', verbose=1, save_best_only=True, mode='min')
callbacks_list = [checkpoint]
# fit the model
model.fit(X, y, epochs=30, batch_size=128, callbacks=callbacks_list)
The full code listing is as follows.
import numpy
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import LSTM
from keras.callbacks import ModelCheckpoint
from keras.utils import np_utils
# load ascii text and covert to lowercase
filename = "../input/alice-wonderland-dataset/alice_in_wonderland.txt"
raw_text = open(filename).read()
raw_text = raw_text.lower()
# create mapping of unique chars to integers
chars = sorted(list(set(raw_text)))
char_to_int = dict((c, i) for i, c in enumerate(chars))
# summarize the loaded data
n_chars = len(raw_text)
n_vocab = len(chars)
print("Total Characters: ", n_chars)
print("Total Vocab: ", n_vocab)
# prepare the dataset of input to output pairs encoded as integers
seq_length = 100
dataX = []
dataY = []
for i in range(0, n_chars - seq_length, 1):
seq_in = raw_text[i:i + seq_length]
seq_out = raw_text[i + seq_length]
dataX.append([char_to_int[char] for char in seq_in])
dataY.append(char_to_int[seq_out])
n_patterns = len(dataX)
print("Total Patterns: ", n_patterns)
# reshape X to be [samples, time steps, features]
X = numpy.reshape(dataX, (n_patterns, seq_length, 1))
# normalize
X = X / float(n_vocab)
# one hot encode the output variable
y = np_utils.to_categorical(dataY)
# define the LSTM model
model = Sequential()
model.add(LSTM(256, input_shape=(X.shape[1], X.shape[2])))
model.add(Dropout(0.2)) model.add(Dense(y.shape[1], activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam')
# define the checkpoint
filepath="weights-improvement1-{epoch:02d}-{loss:.4f}.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='loss', verbose=1, save_best_only=True, mode='min')
callbacks_list = [checkpoint]
# fit the model
model.fit(X, y, epochs=30, batch_size=128, callbacks=callbacks_list)
After running the code, you will get the checkpoints file and we can delete all of them except the one with a small loss.
The weight file that I got after running the training is ‘weights-improvement1-19-1.9435.hdf5’.
For generating the Address, SSN and other fields, we need to train in the same way using another dataset.
- Generating text with LSTM networks-
Next, We are generating text using the LSTM network that we trained before. - Create a new python file and name it document_generator.
- Define the network in exactly the same way and load the data, the weights are loaded from the checkpoints file. There is no need to train the network again.
- Then use the keras LSTM model for prediction.
We need to create the address field, ssn, mrn, patient names and some other details in the generated document. Define checkpoint files and initialise a list for keeping different section names. Define a text file where we need to write data.
#load the network weights
description_file= "../content/weights-improvement-description-30-0.0178.hdf5"
medical_specialty_file = "../content/weights-improvement-medical-49-0.3129.hdf5"
patient_file = "../content/weights-improvement-patient-33-0.0018.hdf5"
ssn_file = "../content/weights-improvement-ssn-13-0.0035.hdf5"
address_file = "../content/weights-improvement-address-13-0.0026.hdf5"
sample_name_file = "../content/weights-improvement-sample-50-0.0620.hdf5"
sections = ['Patient Name', 'SSN', 'Address', 'Description', 'Medical specialty', 'Category']
file_content = ''
file_name = 'patient_medical_data' + '.txt'
file = open('/content/sample_data/' + file_name, 'w')
In order to comprehend the predictions, you must also prepare a reverse mapping that you can use to change the integers back to characters. This reverse mapping must be created while converting unique characters to integers.
#create a reverse mapping, int to char int_to_char = dict((i, c) for i, c in enumerate(chars))
Let’s create different section data based on the section heading. After running below for loop we will get a file which contains patient data. The Keras model provides a load() method to define the model and a compile() method to compile the model. Here we are given the loss function and optimizer as arguments for the compile() function. The Keras model predicts(), is a Keras function that helps in the prediction of output based on the specified samples of input to the model.
#load the network weights
description_file= "../content/weights-improvement-description-30-0.0178.hdf5"
medical_specialty_file = "../content/weights-improvement-medical-49-0.3129.hdf5"
patient_file = "../content/weights-improvement-patient-33-0.0018.hdf5"
ssn_file = "../content/weights-improvement-ssn-13-0.0035.hdf5"
address_file = "../content/weights-improvement-address-13-0.0026.hdf5"
sample_name_file = "../content/weights-improvement-sample-50-0.0620.hdf5"
sections = ['Patient Name', 'SSN', 'Address', 'Description', 'Medical specialty', 'Category']
file_content = ''
file_name = 'patient_medical_data' + '.txt'
file = open('/content/sample_data/' + file_name, 'w')
for section in sections:
if section == 'Patient Name':
model.load_weights(patient_file)
model.compile(loss='categorical_crossentropy', optimizer='adam')
#pick a random seed
start = np.random.randint(0, len(dataX)-1)
pattern = dataX[start]
# generate characters
x = np.reshape(pattern, (1, len(pattern), 1))
x = x / float(n_vocab)
prediction = model.predict(x, verbose=0)
index = np.argmax(prediction)
result = int_to_char[index]
pattern.append(index)
pattern = pattern[1:len(pattern)]
file.write("Patient Name: " + result + '\n')
print("Patient Name:" + result)
elif section == 'SSN':
model_ssn.load_weights(ssn_file)
model_ssn.compile(loss='categorical_crossentropy', optimizer='adam')
#pick a random seed
start = np.random.randint(0, len(dataX_ssn)-1)
pattern = dataX_ssn[start]
# generate characters
x = np.reshape(pattern, (1, len(pattern), 1))
x = x / float(n_vocab)
prediction = model_address.predict(x, verbose=0)
index = np.argmax(prediction)
result = int_to_char_ssn[index]
pattern.append(index)
pattern = pattern[1:len(pattern)]
file.write("SSN: " + result + '\n')
print("SSN: " + result)
elif section == 'Address':
model_address.load_weights(address_file)
model_address.compile(loss='categorical_crossentropy', optimizer='adam')
#pick a random seed
start = np.random.randint(0, len(dataX_address)-1)
pattern = dataX_address[start]
# generate characters
x = np.reshape(pattern, (1, len(pattern), 1))
x = x / float(n_vocab)
prediction = model_address.predict(x, verbose=0)
index = np.argmax(prediction)
result = int_to_char_address[index]
pattern.append(index)
pattern = pattern[1:len(pattern)]
file.write("Address: " + result + '\n')
print("Address: " + result)
elif section == 'Description':
model_description.load_weights(description_file)
model_description.compile(loss='categorical_crossentropy', optimizer='adam')
#pick a random seed
start = np.random.randint(0, len(dataX_description)-1)
pattern = dataX_description[start]
# generate characters
x = np.reshape(pattern, (1, len(pattern), 1))
x = x / float(n_vocab)
prediction = model_description.predict(x, verbose=0)
index = np.argmax(prediction)
result = int_to_char_description[index]
pattern.append(index)
pattern = pattern[1:len(pattern)]
file.write("Description: " + result + '\n')
print("Description:" + result)
elif section == 'Medical specialty':
model_medical_specialty.load_weights(medical_specialty_file)
model_medical_specialty.compile(loss='categorical_crossentropy', optimizer='adam')
#pick a random seed
# start = np.random.randint(0, len(dataX_medical_specialty)-1)
pattern = dataX_medical_specialty[start]
# generate characters
x = np.reshape(pattern, (1, len(pattern), 1))
x = x / float(n_vocab)
prediction = model_medical_specialty.predict(x, verbose=0)
index = np.argmax(prediction)
result = int_to_char_medical_specialty[index]
pattern.append(index)
pattern = pattern[1:len(pattern)]
file.write("Medical specialty: " + result + '\n')
print("Medical specialty:" + result)
elif section == 'Category':
model_sample_name.load_weights(sample_name_file)
model_sample_name.compile(loss='categorical_crossentropy', optimizer='adam')
#pick a random seed
# start = np.random.randint(0, len(dataX_sample_name)-1)
pattern = dataX_sample_name[start]
# generate characters
x = np.reshape(pattern, (1, len(pattern), 1))
x = x / float(n_vocab)
prediction = model_sample_name.predict(x, verbose=0)
index = np.argmax(prediction)
result = int_to_char_sample_name[index]
pattern.append(index)
pattern = pattern[1:len(pattern)]
file.write("Category: " + result + '\n')
print("Category: " + result)
else:
print("Done")
file.flush()
print("\nDone.")
After all these steps, we will have the generated text formatted and ready to be converted into a document.
Now to convert the formatted text into a document, we need to use ImageDraw from the PIL package.
We are underlining words like ssn, mrn, patient name in the document.
Draw.line() function draws lines and the draw.text() function draws text in the document.
mrn_tag_options = ['Medical Record Number', 'MRN', 'MR Number', 'MR #', 'Record Number', 'Record #',
'Medical Record Number\n', '', 'MRN\n', 'MR Number\n', 'MR #\n', 'Record Number\n', 'Record\n']
text2png("/content/sample_data/patient_medical_data.txt")
def text2png(fullpath, color="#000", bgcolor="#FFF", fontfullpath=None, fontsize=18,
leftpadding=25,rightpadding=3, width=1000):
file = open(fullpath, "r")
text = file.read()
print(text)
REPLACEMENT_CHARACTER = u'\uFFFD'
NEWLINE_REPLACEMENT_STRING = ' ' + REPLACEMENT_CHARACTER + ' '
# prepare linkback
linkback = ""
fontlinkback = ImageFont.truetype('/content/arial.ttf', 8)
linkbackx = fontlinkback.getsize(linkback)[0]
linkback_height = fontlinkback.getsize(linkback)[1]
# end of linkback
font = ImageFont.truetype('/content/arial.ttf', 18)
text = text.replace('\n', NEWLINE_REPLACEMENT_STRING)
title_font = ImageFont.truetype('/content/arial.ttf', 24)
sub_title = ImageFont.truetype('/content/arial.ttf', 14)
lines = []
line = u""
for word in text.split():
if word == REPLACEMENT_CHARACTER: # give a blank line
lines.append(line[1:]) # slice the white space in the beginning of the line
line = u""
lines.append(u"") # the blank line
elif font.getsize(line + ' ' + word)[0] <= (width - rightpadding - leftpadding):
line += ' ' + word
else: # start a new linelines.append(line[1:]) # slice the white space in the beginning of the line
line = u""
line += ' ' + word # for now, assume no word alone can exceed the line width
iflen(line) != 0:
lines.append(line[1:]) # add the last line
line_height = font.getsize(text)[1]
img_height = line_height * (len(lines) + 10)
img = Image.new("RGBA", (width, img_height), bgcolor)
draw = ImageDraw.Draw(img)
draw.text((leftpadding + 200, 30), "FAKE DATA ", color, font=title_font)
draw.line((0, 60, width, 60), fill=(0, 0, 0, 128), width=5)
y = 80
has_ssn = False
has_mrn = False
for line in lines:
draw.text((leftpadding, y), line, color, font=font)
y += line_height
if'SSN'in line:
has_ssn = True
if'MRN'in line :
has_mrn = True
mrn_separator = ["/", "&"]
if'SSN'in line or'MRN'in line or'Patient'in line:
draw.line((leftpadding, y - 1, leftpadding + width, y - 1), fill=(random.randint(0, 255),
random.randint(0, 255),random.randint(0, 255), 128), width=2)
mrn_value=["2"]
ifnot has_mrn:
mrn_value = str(random.randint(10, 99)) + mrn_separator[0] + str(random.randint(10, 99))
+ mrn_separator[0] + str(random.randint(1000, 9999))
draw.text((leftpadding + width - 250, 20), mrn_tag_options[0] + " " + mrn_value,color,
font=sub_title)
draw.text((leftpadding, 40), '20/08/2022', color, font=font)
img.save("image.png")
Running this python file will create a patient document.
Let’s see one of the output document images created by the program.

We created a simple document generator using LSTM recurrent neural networks. The efficiency of data generated depends on the model we define. If you would like to know more about the services regarding neural networks, click here.
Disclaimer: The opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Dexlock.



