Let's Discuss
Enquire NowUniversal Embeddings – Elmo
May 16, 2022by, Sanjay S Prabhu
NLP
What exactly are word embeddings?
It’s the process of converting words into vectors. These vectors capture crucial information about the words, allowing words in the same neighborhood in the vector space to have similar meanings. Word embeddings are an important aspect of any NLP model since they give words meaning.
Different tools used for embedding : – Word embeddings can be created using a variety of approaches, including Word2Vec, Continuous Bag of Words (CBOW), Skip Gram, Glove, Elmo, and others.
Word embeddings gave words a precise meaning. Because the meaning of words changes depending on context, this was a key disadvantage of word embeddings, and hence this wasn’t the greatest solution for Language Modeling.
Consider the following sentences as an example.
- The plane landed exactly at 10pm.
- He skidded off a smooth plane surface.
You can see how the meaning of the word plane varies depending on the situation. This necessitated the development of a method for capturing word meaning in a variety of contexts while also retaining contextual information. As a result, contextualized word embeddings were introduced. We’ll see how Embedding for Language Models (ELMo) helped overcome the limitations of standard word embedding approaches like Glove and Word2vec in the sections below.
Embeddings from Language Models(ELMo) :
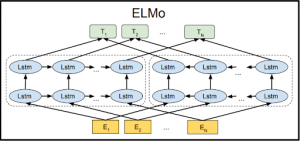
ELMo (Embeddings from Language Models) is a sort of deep contextualized word representation that models both (1) sophisticated features of word use (e.g., syntax and semantics) and (2) how these uses vary across linguistic contexts (i.e., to model polysemy). Word vectors are learned functions of a deep bidirectional language model (biLMinternal )’s states, which have been pre-trained on a huge text corpus.
- AllenNLP created the ELMo NLP framework. A two-layer bidirectional language model is used to calculate ELMo word vectors (biLM). Forward and backward passes are included in each layer.
- ELMo, unlike Glove and Word2Vec, depicts embeddings for a word by using the entire sentence that contains that word. As a result, ELMo embeddings can capture the context of a word in a phrase and generate multiple embeddings for the same word in different contexts in different sentences.
- A forward and backward LM are combined in a biLM. ELMo maximises the log likelihood of both forward and backward directions at the same time. We freeze the weights of the biLM and then concatenate the ELMo vector to add ELMo to a supervised model.
- The network can leverage morphological clues to generate robust representations for out-of-vocabulary tokens that were not seen during training because ELMo word representations are entirely character-based.
- It produces word vectors on the fly, unlike previous word embeddings.
- It embeds anything you type — letters, words, sentences, and paragraphs — but it’s designed specifically for sentence embeddings.
- Rather than employing a fixed embedding for each word, as GloVe does, ELMo examines the entire phrase before assigning an embedding to each word.
How does it accomplish this?
It creates contextual word embedding using a bi-directional Long Short-Term Memory (LSTM) trained on a specific task.
ELMo was a significant step forward in terms of language modeling and comprehension. After been trained on a large dataset, the ELMo LSTM can be used as a component in other NLP models for language modeling.
Elmo employs bi-directional LSTM in its training to ensure that its language model comprehends both the next and previous words in a sentence. It has a bidirectional 2-layer LSTM backbone. Between the first and second layers, a residual connection is added. The use of residual connections allows gradients to flow directly through a network, bypassing the non-linear activation functions. The high-level intuition is that residual connections aid in the training of deep models.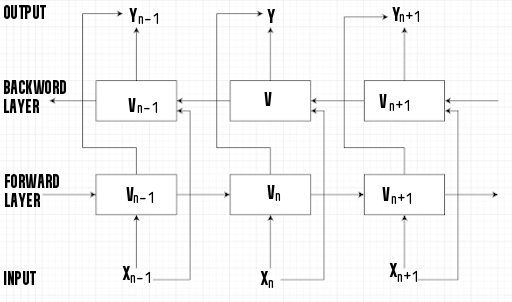
Word embeddings Implementation using ELMo:
Google Colab was used to test the code below. To install the necessary libraries, use these commands before running the code in your terminal.
pip install "tensorflow>=2.0.0" pip install --upgrade tensorflow-hub
Python 3 Code:
# import necessary libraries
import tensorflow_hub as hub
import tensorflow.compat.v1 as tf
tf.disable_eager_execution()
# Load pre trained ELMo model
elmo = hub.Module("https://tfhub.dev/google/elmo/3", trainable=True)
# create an instance of ELMo
embeddings = elmo(
[
"I love to watch TV",
"I am wearing a wrist watch"
],
signature="default",
as_dict=True)["elmo"]
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
# Print word embeddings for word WATCH in given two sentences
print('Word embeddings for word WATCH in first sentence')
print(sess.run(embeddings[0][3]))
print('Word embeddings for word WATCH in second sentence')
print(sess.run(embeddings[1][5]))
|
Output:
Word embeddings for word WATCH in first sentence [ 0.14079645 -0.15788531 -0.00950466 ... 0.4300597 -0.52887094 0.06327899] Word embeddings for word WATCH in second sentence [-0.08213335 0.01050366 -0.01454147 ... 0.48705393 -0.54457957 0.5262399 ]
Explanation: Different word embeddings for the same word WATCH used in distinct contexts in different sentences are shown in the result.
Conclusion
In Natural Language Processing, ELMo has changed the word embedding space (NLP). It’s now a widely used model for a variety of NLP jobs. Hope this post has given you a better understanding of how contextual sentence embeddings function and why ELMo is so effective in language modeling and other NLP tasks. If you would like to know more about our services regarding NLP, click here.
Disclaimer: The opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Dexlock.



