Let's Discuss
Enquire NowFault And Latency Tolerant Analysis Of Time Series Streams Using Apache Spark
Jul 5, 2022by, Akshara B
Data Science
Due to the expansion of the internet and the massive use of mobile devices, the need for processing data in real-time is increasing. Real-time data processing, often known as stream processing, refers to the processing of a continuous stream of data in order to produce an output in real-time. Examples of real-time processing are e-commerce order processing, credit card fraud detection, online booking and reservations etc. Apache Spark is one of the most widely used data processing frameworks available.
Apache Spark:
Apache Spark is a fast cluster computing technology designed for fast computation. It extends the MapReduce model in Hadoop and efficiently uses it for more types of computations, which include interactive queries and stream processing. In-memory cluster computing is the main feature of Apache Spark that increases the processing speed of an application.
Time Series Stream:
In a time-series data set, order and time are fundamentals and they are central to the meaning of data. It helps to analyze how security, asset or economic variables change over time.
Fault and Latency Tolerance:
If the worker where the data receiver is running fails in Spark Streaming, a small amount of data may be lost. As this is data that has been received but has not yet been replicated to other nodes.
Resilient distributed dataset(RDD): This is an immutable distributed collection of any type. It is a fault-tolerant record of data that resides on multiple nodes.
Fault tolerance means RDD has the capability to handle any loss that occurred and can recover from the failure itself. We require a redundant element to recover the lost data. The RDD is capable of recovering from failure. Redundant data is important in the self-recovery process. It allows us to recover lost data.
Spark Streaming Fault Tolerance with receiver-based sources:
- Reliable Receiver:- As soon as the received data has been replicated, reliable sources acknowledge it. In the event that the receiver fails, the source will not acknowledge it for buffered data. As a result, the receiver restarts the next time, and the acknowledgement is automatically sent to the source. There will be no loss as a result of failure.
- UnReliable Receiver:- Unreliable receivers don’t send any kind of acknowledgement. So if any failure occurs the worker or driver causes data loss.
So there is no data loss in the case of reliable receivers. And there is a definite data loss for unreliable receivers.
Spark Streaming Fault Tolerance – Write–ahead logs: Write-ahead logs are used to ensure the durability of any database and file systems and are also called journaling in streaming. To process, an operation is first written down in a durable log, and then applied to the data. If the system fails in the middle of performing an operation, we can easily recover by performing the operations that it was supposed to perform. We can also recover it by reading the log.
Sources like Kafka and Flume use receivers to receive data. Long-running tasks are run by the executors, and it is also responsible for receiving the data from the source. If the source supports it, then it acknowledges the received data. It processes the tasks by running them on the executors and also stores the received data in the memory of the executors and the driver.
When write-ahead logs are enabled, the received data is saved to log files in a fault-tolerant file system. So in spark streaming, it allows the received data to be durable in case of any failure. It ensures zero data loss by either recovering all the data logs or re-sending all data from the sources.
Implementation of Fault Tolerance in Spark Streaming:
While the streaming application is starting, the spark context is used as the starting point of functionality. The connection to the spark cluster is represented by the Spark context. The receivers, on the other hand, receive streaming data and save it in spark’s memory for processing.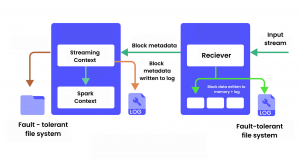
- Receiving data:
A receiver turns the stream of data into blocks and then stores them in the memory of the executor. And also the data are written to a write-ahead log in fault-tolerant file systems if enabled. - Notifying driver:
Sending metadata of received blocks to the streaming context in the driver. Metadata includes, sending block’s reference ids for locating their data in the executor memory and block’s data offset information in the log (if enabled)
- Processing the data:
The streaming context uses the block information to generate jobs and RDDs on them. Spark context processes the in-memory blocks by executing these jobs by running tasks.
- Checkpointing the computation:
Checkpoints the computation to another set of files, this process helps to recover from the failure.
- Recover computation:
It uses the checkpointed information to restart the driver and all receivers. And also uses it to reconstruct the contexts.
- Recover block metadata:
It is necessary to recover the metadata of all blocks to continue the processing.
- Re-generate incomplete jobs:
Some processes may get incomplete due to the failure of the batches. In that case, using the recovered block metadata, it regenerates corresponding jobs & RDDs.
- Read the block saved in the logs:
The block data is read directly from the write-ahead logs when it executes those jobs. It recovers all the important data that was reliably saved to the logs.
- Resend unacknowledged data:
Buffered data that was not saved to the log will be resent by the source, at the time of failure, because the receiver does not acknowledge it.
Latency Tolerance in Spark Streaming:
- Latency is another important factor in stream processing. If we can react to event patterns in milliseconds, we can avoid the challenge of fraud detection in banking and other security applications. However, when latencies exceed 100 milliseconds, it may be less valuable because we are only detecting after something has happened.
- By default, Structured Streaming uses a micro-batch execution model. In this case, the Spark streaming engine checks the streaming source on a regular basis and runs a batch query whenever new data arrives since the last batch ended. This will allow us to achieve high throughput with latencies as low as 100ms.
- In Continuous Processing mode, Instead of running tasks on a regular basis, Spark launches a set of long-running tasks that continuously read, process, and write data. End-to-end latency is a few milliseconds here because events are processed and written to sink as soon as they become available.
Conclusion
The fault tolerance property of Apache Spark ensures that no data is lost due to driver failure. This is attained with the help of write-ahead logs and reliable receivers. The fault and latency tolerance properties of Spark streaming improve the efficiency of the system.
Disclaimer: The opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Dexlock.



