Let's Discuss
Enquire NowLifelike Speech Synthesis (Text To Speech)
Aug 24, 2022by, Aman O
Machine Learning
The first computer-based TTS (Text To Speech) system was in the late 1960s when the researchers were able to recreate the song Daisy Bell, and this was a very significant innovation as this opened up a lot of possibilities in a variety of fields. The only issue with these TTS systems was that they all sounded very robotic and completely different from how human beings communicate. With the modern advancements in Machine Learning and advances in Deep Neural Networks (DNN), this domain was transformed and algorithms capable of generating lifelike speech were developed. This also expanded the applications where such software could be used. With current technology in certain cases distinguishing human speech from computer-generated speech has become exceedingly difficult as computers seem to be able to generate human speech to such a high level of accuracy.
Text To Speech Architecture
Several architectures exist for TTS with the most prominent being concatenation synthesis and parametric synthesis.
Concatenation synthesis
The concatenation of pre-recorded speech segments is the basis for concatenation synthesis. Full phrases, words, syllables, diphones, and even individual phones can be used as segments and are usually stored in the form of waveforms or spectrograms.
Segments are acquired through speech recognition and are labeled based on their acoustic properties. The intended sequence is generated at runtime by selecting the best chain of candidate units from the database.
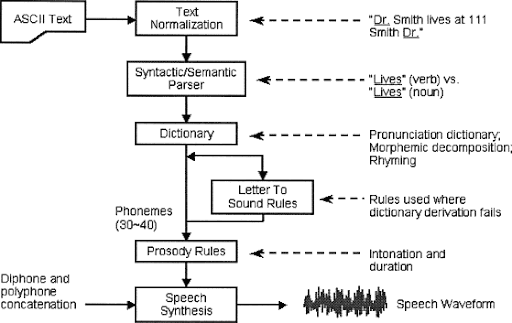
Block diagram for Concatenative Synthesis
Statistical Parametric Synthesis
Parametric synthesis utilizes recorded human voices as well. The distinction is that we change the voice using a function and a set of parameters. We usually have two pieces in statistical parametric synthesis. The training and the synthesis. During training, we extract a set of parameters that characterize the audio sample such as the frequency spectrum, fundamental frequency, and duration of the speech. Using a statistical model, we then try to estimate these parameters.
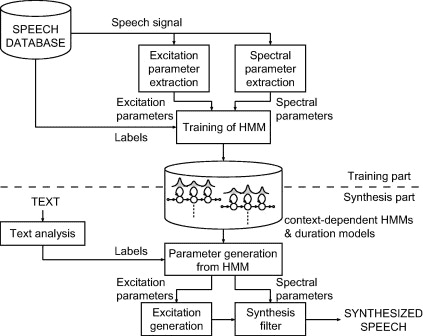
WaveNet Synthesis Model
WaveNet, a deep generative model of raw audio waveforms is a newer TTS architecture that is capable of generating speech that mimics the human voice and sounds more natural than any other TTS system. It’s a fully convolutional neural network with multiple dilation factors in the convolutional layers, allowing the receptive field to grow exponentially with depth and cover thousands of timesteps.
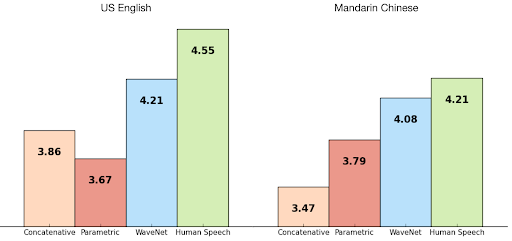
Wavenet vs other synthetic voices, human speech. The y-axis values represent the Mean Opinion Score (MOS) for each voice given by test takers on a scale of 1-5
Source: Google Cloud
A WaveNet model, unlike most other text-to-speech systems, creates raw audio waveforms from scratch. The model is based on a neural network that was trained on a huge number of voice samples. The trained WaveNet model can create equivalent voice waveforms from scratch, one sample at a time, with up to 24,000 samples per second.
Modelling raw audio is usually avoided by researchers as it ticks so quickly with more than 16,000 samples per second. So building a completely autoregressive model, in which the prediction for every one of those samples is influenced by all previous ones is a very challenging task.
The PixelRNN and PixelCNN models published recently showed that it was possible to generate complex natural images not only one pixel at a time, but one colour channel at a time, requiring thousands of predictions per image. This paved the way for modelling the WaveNet.

Lifelike Speech Synthesis Use Cases
Lifelike speech synthesis has opened up a plethora of opportunities where this technology can be used to make tasks easier and more efficient.
During synthesis, HMMs generate a set of parameters from our target text sequence which are then used to synthesize the final speech waveforms.
Virtual Personal Assistant
Virtual Personal Assistants like Google Assistant, Amazon Alexa, and Siri all have become staples in our lives as every phone in the current generation have these built in to make lives easier. Features such as the ability to converse with your phone and set up an automatic answering of phone calls by the assistant are available to make tasks easier and improve our efficiency.
Communication for people with disabilities
Speech synthesis has allowed people with disabilities that prevent them from communicating effectively to overcome their limitations by using speech synthesis programs to perform communication for them. An example of this can be seen in the late Scientist Stephen Hawking who had contracted an incurable degenerative neuromuscular disease that paralyzed his body. He was however able to publish several books and conduct talks with the help of speech synthesis. His contributions to the field of Quantum Mechanics, Origins of the Universe, and Black Holes have helped in making advancements in the field.
Video Games for speech synthesis
Videogames have seen increasing popularity with Covid-19 and becoming a social space for people to have fun while being confined to their homes. Most video games make use of large amounts of speech in the form of dialogues and conversations within the game. Historically this is something that is done with the help of a voice actor who will be performing all the discussions, but with speech synthesis we would be able to generate a lot of the speech without any human requirement as well as the ability to generate different speech on the go, which was not previously possible.
Machine Learning Audio frameworks
Several OpenSource Machine Learning Audio frameworks allow us to generate our speech synthesis application. However, training our custom voices for audio use cases is extremely GPU intensive due to the DNN requirements and may take days or even weeks to complete. Pretrained voices are available and may be used for our applications without having to perform many resource-intensive and time-consuming tasks.
Some popular frameworks are given below
- TensorFlow TTS
Allows us to make TTS models that can be run faster in real-time with the ability to be deployed on mobile devices and embedded systems with ease.
Tensorflow 2 provides for a much faster training and inference process which if further optimized using fake-quantize aware and pruning. - ESPnet
ESPnet is an end-to-end speech processing toolkit covering end-to-end speech recognition, text-to-speech, speech translation, speech enhancement, speaker diarization, spoken language understanding, etc.
Has a built-in Automatic Speech Recognition (ASR) model.
Has the largest TTS Open Source active community - Cloud Solutions
Cloud solutions for TTS are available and provided by several corporations like Google, Microsoft, and Amazon. These cost a specific amount based on the characters used to generate speech mostly on a per month basis. - Google Cloud Text to Speech
Google Cloud Text-to-Speech enables developers to synthesize natural-sounding speech with several voices, available in multiple languages and variants. It also provides us with WaveNet-based TTS that is capable of generating the highest quality of TTS using Google’s powerful neural networks. It is available as an easy-to-use API that allows us to create lifelike interactions across many applications and devices.
The WaveNet-based TTS system is used by Google’s virtual private assistant Google Assistant to generate lifelike speech.Key Features
- Custom Voice
- Google TTS allows us to train a custom voice model using our audio recordings to create a unique and more natural-sounding voice.
- WaveNet voices
The WaveNet model discussed earlier is available through google cloud TTS. Though it costs more than a generic TTS system the output it provides is much more natural sounding than other text-to-speech systems. It synthesizes speech by emphasizing syllables, phonemes, and words in a more human-like manner. - Voice tuning
It provides the ability to personalize the pitch of our selected voice, up to 20 semitones more or less from the default. This allows us to adjust the speaking rate to be faster or slower than the normal rate.
Pricing
Standard (non-WaveNet) voices
0 to 4 million characters
$0.000004 per character ($4.00 per 1 million characters)
WaveNet voices
0 to 1 million characters
$0.000016 per character ($16.00 per 1 million characters)
- Microsoft Azure Text to speech
Azure TTS can provide more than 270 neural voices in 119 languages and variants, as well as customized voices, and access voices with various speaking styles and emotional tones to match various use cases.
Key Features
- Tailored speech output
We can fine-tune synthesized speech audio to fit different scenarios. We can define lexicons and control speech parameters such as pronunciation, pitch, rate, pauses, and intonation.
Ability to Deploy from anywhere, from the cloud to the edge
Provides the capability to run TTS wherever the data resides. Docker containers may also be used to build lifelike speech synthesis into applications optimized for robust cloud capabilities and edge locality. - Amazon Polly
Amazon Polly is a service that converts text into natural-sounding voice, allowing us to create talking apps and new categories of speech-enabled devices. It makes use of advanced deep learning technology, to synthesize natural-sounding human speech. The popular Amazon Alexa voice assistant uses this for its well-renowned lifeline speech.Key Features - Simple-to-Use API
Amazon Polly provides an API that enables us to quickly integrate speech synthesis into our application. The text to be translated into speech is submitted to the Amazon Polly API, which returns the audio stream to your application quickly, allowing our application to continue working. - Wide Selection of Voices and Languages
Amazon Polly includes dozens of lifelike voices and support for various languages so that we can select the ideal voice and distribute your speech-enabled applications in many countries. Amazon Polly also offers Neural Text-to-Speech (NTTS) voices that improve speech quality for more natural and human-like voices. - Synchronize Speech for an Enhanced Visual Experience
Amazon Polly makes it simple to request an extra stream of metadata that tells you when specific sentences, words, and sounds are being pronounced. Using this metadata stream alongside the synthesized speech audio stream, we can now build applications with an enhanced visual experience, such as speech-synchronized facial animation or karaoke-style word highlighting.
The technologies and tools that we have explored in this article portray how far we have progressed in the field of speech synthesis. We can get an idea of the tools to synthesize speech on our own for any of our applications and also about how our personal assistants sound so realistic. If you would like to know more about our resources, click here.
Disclaimer: The opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Dexlock.



